
[TOC]
# RabbitMq怎么保证高可用
RabbitMQ是一个比较有代表性的消息中间件,因为是基于主从做的高可用架构、我们就以它为例子来聊下其高可用是如何实现的。
RabbitMQ有三种模式:单机模式、普通集群模式、镜像集群模式。
## 1.1 单机模式
单机模式就是处于一种demo模式、一般就是自己本地搞一个玩玩,生产环境没有那个哥们会使用单机模式的。
## 1.2 普通集群模式
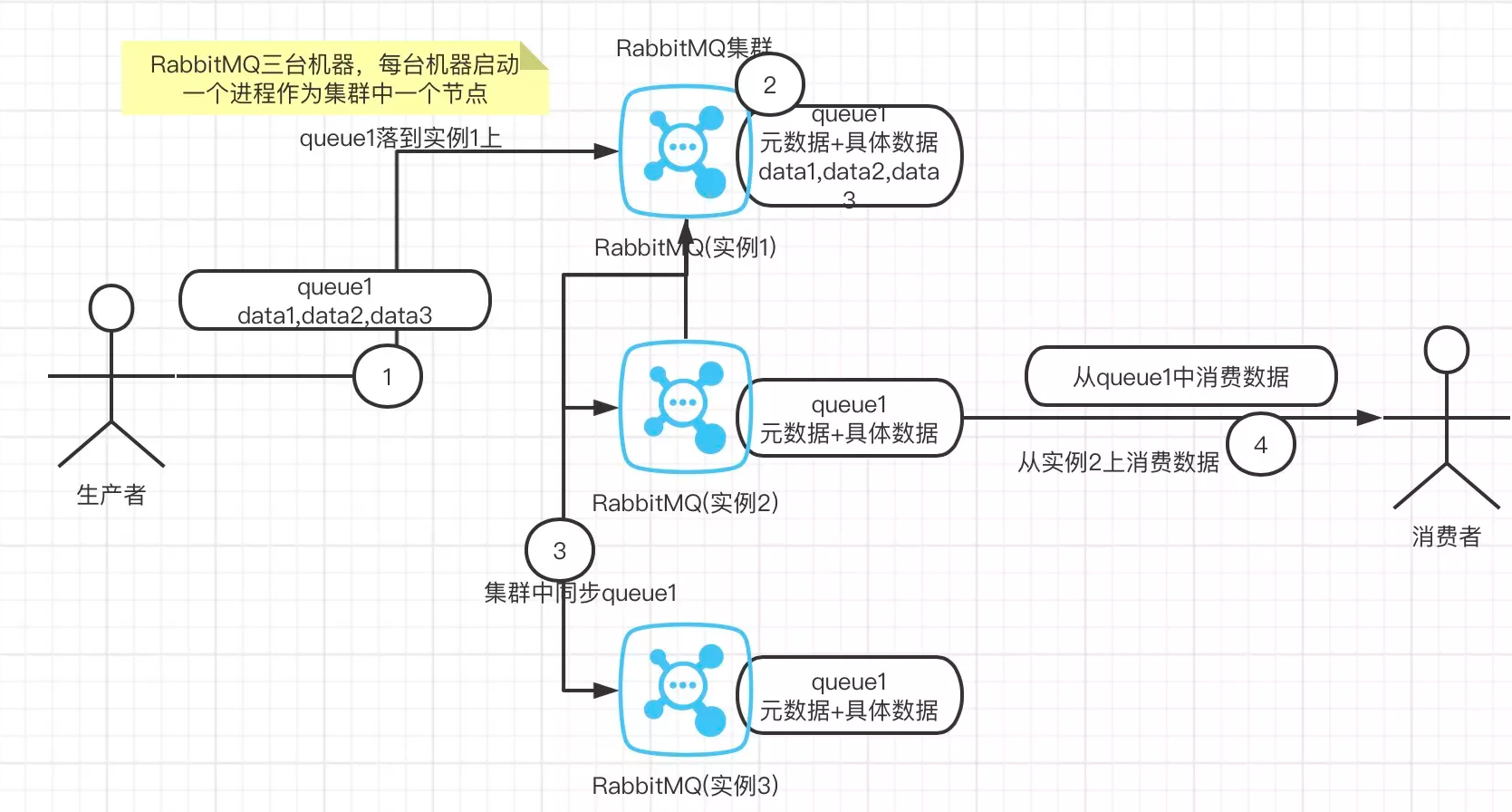
 ](images/screenshot_1615898622499.png)
如上图是普通集群模式
1、RabbitMQ在多台服务器启动实例、每台服务器一个实例、当你创建queue时、queue(元数据+具体数据)只会落在一台RabbitMQ实例上、但是集群中每个实例都会同步queue的元数据(元数据:真实数据的描述如具体位置等)。
2、当用户消费时如果连接的是另外一个实例,当前实例会根据同步的元数据找到具体的数据所在的实例从其上把具体数据拉过来消费。
这种方式的缺点很明显,没有做到所谓的分布式、只是一个普通的集群。这种方式在消费数据时要么随机选择一个实例拉去数据、要么固定连接那个queue所在的实例来拉取数据,前者导致一次实例见拉取数据的开销、而后在会导致单实例性能的瓶颈。
而且如果存放数据的queue的实例宕机了、会导致其它实例无法从该实例来拉取数据了,如果你开启了RabbitMQ的持久化功能,消息不一定会丢失,但是得等待这个实例重启后才能继续从该queue拉取数据。
所以总的来说这事就比较尴尬了,就完全没有所谓的高可用一说了,这个方案主要的目的是提高吞吐量的,就是说让集群中的多个节点来服务某个queue的读写操作。
## 1.3镜像集群模式
这种集群模式真正达到了RabbitMQ高可用性,和普通集群不一样的是你创建的queue不管是元数据还是里面的具体消息都会存在于所有的实例上。每次写消息时都会把消息同步到每个节点的queue中去。
这种方式的优点在于,你任何一个节点宕机了、都没事儿,别的节点都还可以正常使用。
缺点:
1、性能开销太大,消息同步到所有的节点服务器会导致网络带宽压力和消耗很严重。
2、这种模式没有扩展性可言,如果你某个queue的负载很高,你加机器,新增的机器也包含了这个queue的所有数据,并没有办法线性扩展你的queue.
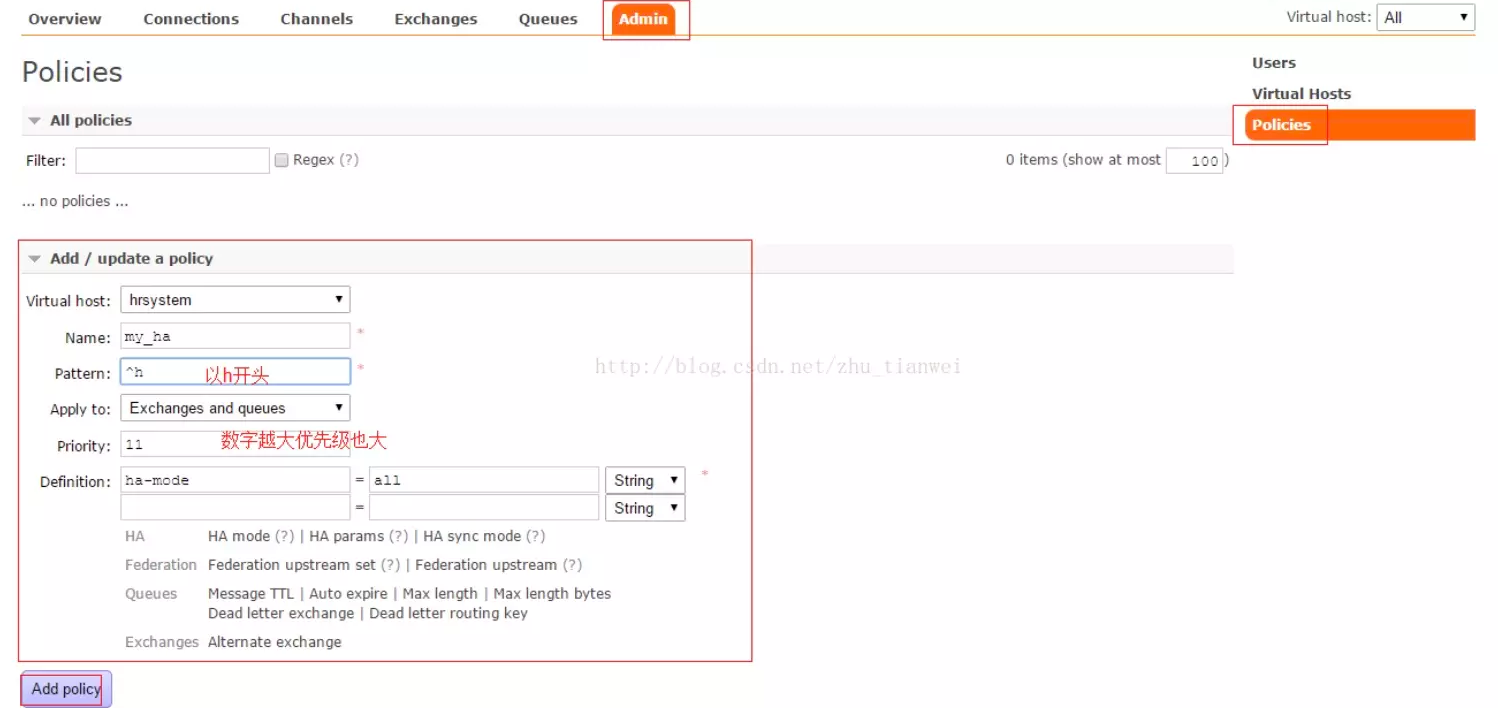
这里在多说下如何开启镜像集群模式?其实开启很简单在RabbitMQ的管理控制台,新增一条策略、这个策略就是开启开启镜像集群模式策略、指定的时候可以指定数据同步到所有的节点,也可以要求同步到指定的节点数量,之后你在创建queue时使用这个策略、就会在动降数据同步到其它节点上去了。
# Zookeeper怎么支持高可用
**高可用**:Zookeeper 系统中只要集群中存在超过一半的节点(这里指的是投票节点即非 Observer 节点)能够正常工作,那么整个集群就能够正常对外服务
# Redis怎么保证高可用
## 1.如何保证Redis高可用和高并发?
Redis主从架构,一主多从,可以满足高可用和高并发。出现实例宕机自动进行主备切换,配置读写分离缓解Master读写压力。
## 2.Redis高可用方案具体怎么实施?
使用官方推荐的哨兵(sentinel)机制就能实现,当主节点出现故障时,由Sentinel自动完成故障发现和转移,并通知应用方,实现高可用性。它有四个主要功能:
* 集群监控,负责监控redis master和slave进程是否正常工作。
* 消息通知,如果某个redis实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
* 故障转移,如果master node挂掉了,会自动转移到slave node上。
* 配置中心,如果故障转移发生了,通知client客户端新的master地址。
## 3.你能说说Redis哨兵机制的原理吗?
通过sentinel模式启动redis后,自动监控master/slave的运行状态,基本原理是:心跳机制+投票裁决。每个sentinel会向其它sentinal、master、slave定时发送消息,以确认对方是否活着,如果发现对方在指定时间内未回应,则暂时认为对方宕机。若哨兵群中的多数sentinel都报告某一master没响应,系统才认为该master真正宕机,通过Raft投票算法,从剩下的slave节点中,选一台提升为master,然后自动修改相关配置。
# Kafka怎么保证高可用
Kafka不是完全同步,也不是完全异步,是一种特殊的ISR(In Sync Replica)。
ISR(in-sync replica) 就是 Kafka 为某个分区维护的一组同步集合,即每个分区都有自己的一个 ISR 集合,处于 ISR 集合中的副本,意味着 follower 副本与 leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 leader。
## Kafka的Replica
1. kafka的topic可以设置有n个副本(replica),副本数最好要小于等于broker的数量,也就是要保证一个broker上的replica最多有一个。
2. 创建副本的单位是topic的分区,每个分区有1个leader和0到n-1follower,Kafka把多个replica分为Lerder replica和follower replica。
3. 当producer在向topic partition中写数据时,根据ack机制,默认ack=1,只会向leader中写入数据,然后leader中的数据会复制到其他的replica中,follower会周期性的从leader中pull数据,但是对于数据的读写操作都在leader replica中,follower副本只是当leader副本挂了后才重新选取leader,follower并不向外提供服务。
## Kafka ISR机制
**ISR副本:** 就是能跟首领副本基本保持一致的跟随副本,如果同步的速度太慢的话,就会被踢出ISR副本。
**副本同步:**
* LEO(last end offset):日志末端位移,记录了该副本对象底层日志文件中下一条消息的位移值,副本写入消息的时候,会自动更新 LEO 值。如果LE0 为2的时候,当前的offset为1。
* HW(high watermark):高水印值,HW 一定不会大于 LEO 值,小于 HW 值的消息被认为是“已提交”或“已备份”的消息,并对消费者可见。
* producer向leader发送消息,之后写入到leader,leader在本地生成log,之后follow从leader拉取消息,follow写入到本地的log中,会给leader返回一个ack信号,一旦收到了ISR中的所有的ack信号,就会增加HW,然后leader返回给producer一个ack。
## Kafka的复制机制
kafka 每个分区都是由顺序追加的不可变的消息序列组成,每条消息都一个唯一的offset 来标记位置。
kafka中的副本机制是以分区粒度进行复制的,在kafka中创建 topic的时候,都可以设置一个复制因子(replica count),这个复制因子决定着分区副本的个数,如果leader 挂掉了,kafka 会把分区主节点failover到其他副本节点,这样就能保证这个分区的消息是可用的。leader节点负责接收producer 发过来的消息,其他副本节点(follower)从主节点上拷贝消息。
\[站外图片上传中...(image-31f1f9-1614765714779)\]
kakfa 日志复制算法提供的保证是当一条消息在producer端认为已经committed的之后,如果leader 节点挂掉了,其他节点被选举成为了 leader 节点后,这条消息同样是可以被消费到的。
**关键配置:** [unclean.leader.election.enable](https://kafka.apache.org/documentation/#brokerconfigs_unclean.leader.election.enable)
~~~
Indicates whether to enable replicas not in the ISR set to be elected as leader as a last resort,
even though doing so may result in data loss
Type: boolean
Default: false
Valid Values:
Importance: high
Update Mode: cluster-wide
~~~
默认为 `false`, 即允许不在isr中replica选为leader,这个配置可以全局配置,也可以在topic级别配置。
这样的话,leader选举的时候,只能从ISR集合中选举,集合中的每个点都必须是和leader消息同步的,也就是没有延迟,分区的leader 维护ISR 集合列表,如果某个点落后太多,就从 ISR集合中踢出去。
producer 发送一条消息到leader节点后, 只有当ISR中所有Replica都向leader发送ACK确认这条消息时,leader才commit,这时候producer才能认为这条消息commit了,正是因为如此,kafka客户端的写性能取决于ISR集合中的最慢的一个broker的接收消息的性能,如果一个点性能太差,就必须尽快的识别出来,然后从ISR集合中踢出去,以免造成性能问题。
**如何判断副本不会被移除ISR集合?**
`replica.lag.max.messages` : follower副本最大落后leader副本的消息数。(0.9.0.0版本后移除)。
`replica.lag.time.max.ms`: 不仅指自从上次从副本获取请求以来经过的时间,而且还指自上次捕获副本以来的时间。
设置`replica.lag.max.messages`为3,只要 follower 只要不落后leader 大于2条消息,就然后是跟得上leader的节点,就不会被踢出去。
设置 replica.lag.time.max.ms 为 300ms, 意味着只要 follower 在每 300ms内发送fetch请求,就不会被认为已经dead ,不会从ISR集合中踢出去。
## 结语
Replica的目的就是在发生意外时及时顶上,leader失效后,就需要从follower中马上选一个新的leader 。选举时优先从ISR中选定,因为这个列表中follower的数据是与leader同步的,从他们中间选取可以保证数据完整 。
但如果不幸ISR列表中的follower都不行了,就只能从其他follower中选取,这时就有数据丢失的可能了,因为不确定这个follower是否已经把leader的数据都复制完成了。
还有一种极端情况,就是所有副本都失效了,这时有两种方案:
* 等待ISR中的一个活过来,选为Leader,数据可靠,但活过来的时间不确定 。
* 选择第一个活过来的Replication,不一定是ISR中的,选为leader,以最快速度恢复可用性,但数据不一定完整。
Kafka支持通过配置选择使用哪一种方案,可以根据可用性和一致性进行权衡。
# Zookeeper的CAP
CAP理论告诉我们,一个分布式系统不可能同时满足以下三种
一致性(C:Consistency)
可用性(A:Available)
分区容错性(P:Partition Tolerance)
这三个基本需求,最多只能同时满足其中的两项,因为P是必须的,因此往往选择就在CP或者AP中。
**在此ZooKeeper保证的是CP**
分析:可用性(A:Available)
**不能保证每次服务请求的可用性**。任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。所以说,ZooKeeper不能保证服务可用性。
**进行leader选举时集群都是不可用**。在使用ZooKeeper获取服务列表时,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。所以说,ZooKeeper不能保证服务可用性。
————————————————
- 一.JVM
- 1.1 java代码是怎么运行的
- 1.2 JVM的内存区域
- 1.3 JVM运行时内存
- 1.4 JVM内存分配策略
- 1.5 JVM类加载机制与对象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面试相关文章
- 2.1 可能是把Java内存区域讲得最清楚的一篇文章
- 2.0 GC调优参数
- 2.1GC排查系列
- 2.2 内存泄漏和内存溢出
- 2.2.3 深入理解JVM-hotspot虚拟机对象探秘
- 1.10 并发的可达性分析相关问题
- 二.Java集合架构
- 1.ArrayList深入源码分析
- 2.Vector深入源码分析
- 3.LinkedList深入源码分析
- 4.HashMap深入源码分析
- 5.ConcurrentHashMap深入源码分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的设计模式
- 8.集合架构之面试指南
- 9.TreeSet和TreeMap
- 三.Java基础
- 1.基础概念
- 1.1 Java程序初始化的顺序是怎么样的
- 1.2 Java和C++的区别
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字节与字符的区别以及访问修饰符
- 1.7 深拷贝与浅拷贝
- 1.8 字符串常量池
- 2.面向对象
- 3.关键字
- 4.基本数据类型与运算
- 5.字符串与数组
- 6.异常处理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 数据流(Stream)
- 8.3 Java 8 并发教程:线程和执行器
- 8.4 Java 8 并发教程:同步和锁
- 8.5 Java 8 并发教程:原子变量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、数值、算术和文件
- 8.7 在 Java 8 中避免 Null 检查
- 8.8 使用 Intellij IDEA 解决 Java 8 的数据流问题
- 四.Java 并发编程
- 1.线程的实现/创建
- 2.线程生命周期/状态转换
- 3.线程池
- 4.线程中的协作、中断
- 5.Java锁
- 5.1 乐观锁、悲观锁和自旋锁
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平锁和非公平锁
- 5.3.1 说说ReentrantLock的实现原理,以及ReentrantLock的核心源码是如何实现的?
- 5.5 锁优化和升级
- 6.多线程的上下文切换
- 7.死锁的产生和解决
- 8.J.U.C(java.util.concurrent)
- 0.简化版(快速复习用)
- 9.锁优化
- 10.Java 内存模型(JMM)
- 11.ThreadLocal详解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的实现原理
- 1.DelayQueue的实现原理
- 14.Thread.join()实现原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的实际使用场景
- 五.Java I/O NIO
- 1.I/O模型简述
- 2.Java NIO之缓冲区
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之选择器
- 6.基于 Java NIO 实现简单的 HTTP 服务器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面试题
- 六.Java设计模式
- 1.单例模式
- 2.策略模式
- 3.模板方法
- 4.适配器模式
- 5.简单工厂
- 6.门面模式
- 7.代理模式
- 七.数据结构和算法
- 1.什么是红黑树
- 2.二叉树
- 2.1 二叉树的前序、中序、后序遍历
- 3.排序算法汇总
- 4.java实现链表及链表的重用操作
- 4.1算法题-链表反转
- 5.图的概述
- 6.常见的几道字符串算法题
- 7.几道常见的链表算法题
- 8.leetcode常见算法题1
- 9.LRU缓存策略
- 10.二进制及位运算
- 10.1.二进制和十进制转换
- 10.2.位运算
- 11.常见链表算法题
- 12.算法好文推荐
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事务管理
- 4.SpringMVC 运行流程和手动实现
- 0.Spring 核心技术
- 5.spring如何解决循环依赖问题
- 6.springboot自动装配原理
- 7.Spring中的循环依赖解决机制中,为什么要三级缓存,用二级缓存不够吗
- 8.beanFactory和factoryBean有什么区别
- 九.数据库
- 1.mybatis
- 1.1 MyBatis-# 与 $ 区别以及 sql 预编译
- Mybatis系列1-Configuration
- Mybatis系列2-SQL执行过程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-参数设置揭秘(ParameterHandler)
- Mybatis系列8-缓存机制
- 2.浅谈聚簇索引和非聚簇索引的区别
- 3.mysql 证明为什么用limit时,offset很大会影响性能
- 4.MySQL中的索引
- 5.数据库索引2
- 6.面试题收集
- 7.MySQL行锁、表锁、间隙锁详解
- 8.数据库MVCC详解
- 9.一条SQL查询语句是如何执行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能优化神器 Explain 使用分析
- 12.mysql中,一条update语句执行的过程是怎么样的?期间用到了mysql的哪些log,分别有什么作用
- 十.Redis
- 0.快速复习回顾Redis
- 1.通俗易懂的Redis数据结构基础教程
- 2.分布式锁(一)
- 3.分布式锁(二)
- 4.延时队列
- 5.位图Bitmaps
- 6.Bitmaps(位图)的使用
- 7.Scan
- 8.redis缓存雪崩、缓存击穿、缓存穿透
- 9.Redis为什么是单线程、及高并发快的3大原因详解
- 10.布隆过滤器你值得拥有的开发利器
- 11.Redis哨兵、复制、集群的设计原理与区别
- 12.redis的IO多路复用
- 13.相关redis面试题
- 14.redis集群
- 十一.中间件
- 1.RabbitMQ
- 1.1 RabbitMQ实战,hello world
- 1.2 RabbitMQ 实战,工作队列
- 1.3 RabbitMQ 实战, 发布订阅
- 1.4 RabbitMQ 实战,路由
- 1.5 RabbitMQ 实战,主题
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 实战 – 整合 RabbitMQ 发送邮件
- 1.8 RabbitMQ 的消息持久化与 Spring AMQP 的实现剖析
- 1.9 RabbitMQ必备核心知识
- 2.RocketMQ 的几个简单问题与答案
- 2.Kafka
- 2.1 kafka 基础概念和术语
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志机制
- 2.4 kafka是pull还是push的方式传递消息的?
- 2.5 Kafka的数据处理流程
- 2.6 Kafka的脑裂预防和处理机制
- 2.7 Kafka中partition副本的Leader选举机制
- 2.8 如果Leader挂了的时候,follower没来得及同步,是否会出现数据不一致
- 2.9 kafka的partition副本是否会出现脑裂情况
- 十二.Zookeeper
- 0.什么是Zookeeper(漫画)
- 1.使用docker安装Zookeeper伪集群
- 3.ZooKeeper-Plus
- 4.zk实现分布式锁
- 5.ZooKeeper之Watcher机制
- 6.Zookeeper之选举及数据一致性
- 十三.计算机网络
- 1.进制转换:二进制、八进制、十六进制、十进制之间的转换
- 2.位运算
- 3.计算机网络面试题汇总1
- 十四.Docker
- 100.面试题收集合集
- 1.美团面试常见问题总结
- 2.b站部分面试题
- 3.比心面试题
- 4.腾讯面试题
- 5.哈罗部分面试
- 6.笔记
- 十五.Storm
- 1.Storm和流处理简介
- 2.Storm 核心概念详解
- 3.Storm 单机版本环境搭建
- 4.Storm 集群环境搭建
- 5.Storm 编程模型详解
- 6.Storm 项目三种打包方式对比分析
- 7.Storm 集成 Redis 详解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初识ElasticSearch
- 2.文档基本CRUD、集群健康检查
- 3.shard&replica
- 4.document核心元数据解析及ES的并发控制
- 5.document的批量操作及数据路由原理
- 6.倒排索引
- 十七.分布式相关
- 1.分布式事务解决方案一网打尽
- 2.关于xxx怎么保证高可用的问题
- 3.一致性hash原理与实现
- 4.微服务注册中心 Nacos 比 Eureka的优势
- 5.Raft 协议算法
- 6.为什么微服务架构中需要网关
- 0.CAP与BASE理论
- 十八.Dubbo
- 1.快速掌握Dubbo常规应用
- 2.Dubbo应用进阶
- 3.Dubbo调用模块详解
- 4.Dubbo调用模块源码分析
- 6.Dubbo协议模块