
# 线性数据结构
> 开头还是求点赞,求转发!原创优质公众号,希望大家能让更多人看到我们的文章。
>
> 图片都是我们手绘的,可以说非常用心了!
## 1. 数组
**数组(Array)** 是一种很常见的数据结构。它由相同类型的元素(element)组成,并且是使用一块连续的内存来存储。
我们直接可以利用元素的索引(index)可以计算出该元素对应的存储地址。
数组的特点是:**提供随机访问** 并且容量有限。
```java
假如数组的长度为 n。
访问:O(1)//访问特定位置的元素
插入:O(n )//最坏的情况发生在插入发生在数组的首部并需要移动所有元素时
删除:O(n)//最坏的情况发生在删除数组的开头发生并需要移动第一元素后面所有的元素时
```

## 2. 链表
### 2.1. 链表简介
**链表(LinkedList)** 虽然是一种线性表,但是并不会按线性的顺序存储数据,使用的不是连续的内存空间来存储数据。
链表的插入和删除操作的复杂度为 O(1) ,只需要知道目标位置元素的上一个元素即可。但是,在查找一个节点或者访问特定位置的节点的时候复杂度为 O(n) 。
使用链表结构可以克服数组需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但链表不会节省空间,相比于数组会占用更多的空间,因为链表中每个节点存放的还有指向其他节点的指针。除此之外,链表不具有数组随机读取的优点。
### 2.2. 链表分类
**常见链表分类:**
1. 单链表
2. 双向链表
3. 循环链表
4. 双向循环链表
```java
假如链表中有n个元素。
访问:O(n)//访问特定位置的元素
插入删除:O(1)//必须要要知道插入元素的位置
```
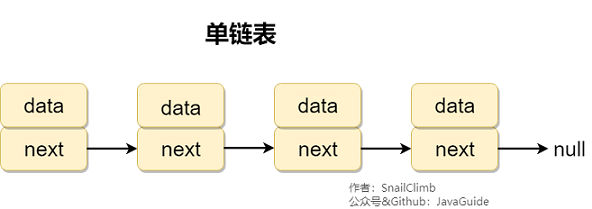
#### 2.2.1. 单链表
**单链表** 单向链表只有一个方向,结点只有一个后继指针 next 指向后面的节点。因此,链表这种数据结构通常在物理内存上是不连续的。我们习惯性地把第一个结点叫作头结点,链表通常有一个不保存任何值的 head 节点(头结点),通过头结点我们可以遍历整个链表。尾结点通常指向 null。
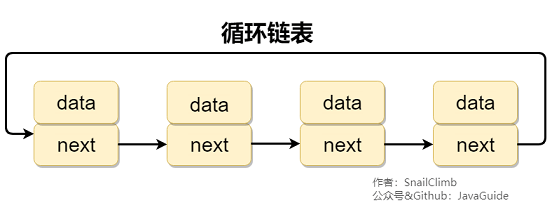
#### 2.2.2. 循环链表
**循环链表** 其实是一种特殊的单链表,和单链表不同的是循环链表的尾结点不是指向 null,而是指向链表的头结点。
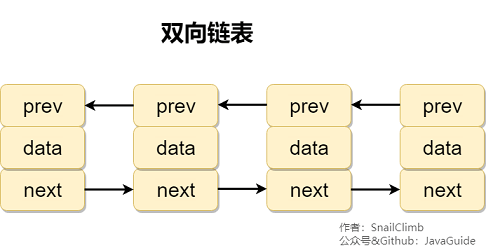
#### 2.2.3. 双向链表
**双向链表** 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
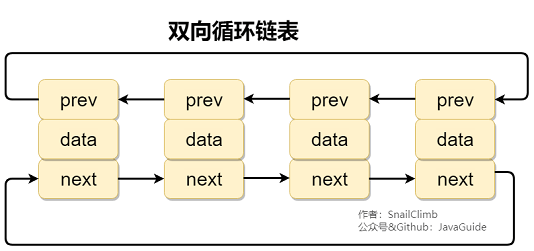
#### 2.2.4. 双向循环链表
**双向循环链表** 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
### 2.3. 应用场景
- 如果需要支持随机访问的话,链表没办法做到。如
- 果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
### 2.4. 数组 vs 链表
- 数据支持随机访问,而链表不支持。
- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
- 数据的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
## 3. 栈
### 3.1. 栈简介
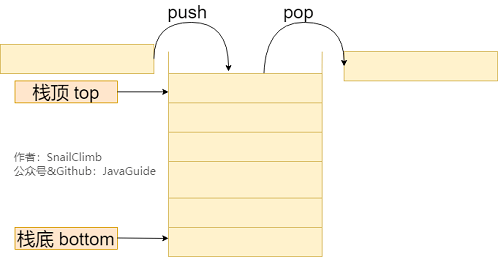
**栈** (stack)只允许在有序的线性数据集合的一端(称为栈顶 top)进行加入数据(push)和移除数据(pop)。因而按照 **后进先出(LIFO, Last In First Out)** 的原理运作。**在栈中,push 和 pop 的操作都发生在栈顶。**
栈常用一维数组或链表来实现,用数组实现的栈叫作 **顺序栈** ,用链表实现的栈叫作 **链式栈** 。
```java
假设堆栈中有n个元素。
访问:O(n)//最坏情况
插入删除:O(1)//顶端插入和删除元素
```
### 3.2. 栈的常见应用常见应用场景
当我们我们要处理的数据只涉及在一端插入和删除数据,并且满足 **后进先出(LIFO, Last In First Out)** 的特性时,我们就可以使用栈这个数据结构。
#### 3.2.1. 实现浏览器的回退和前进功能
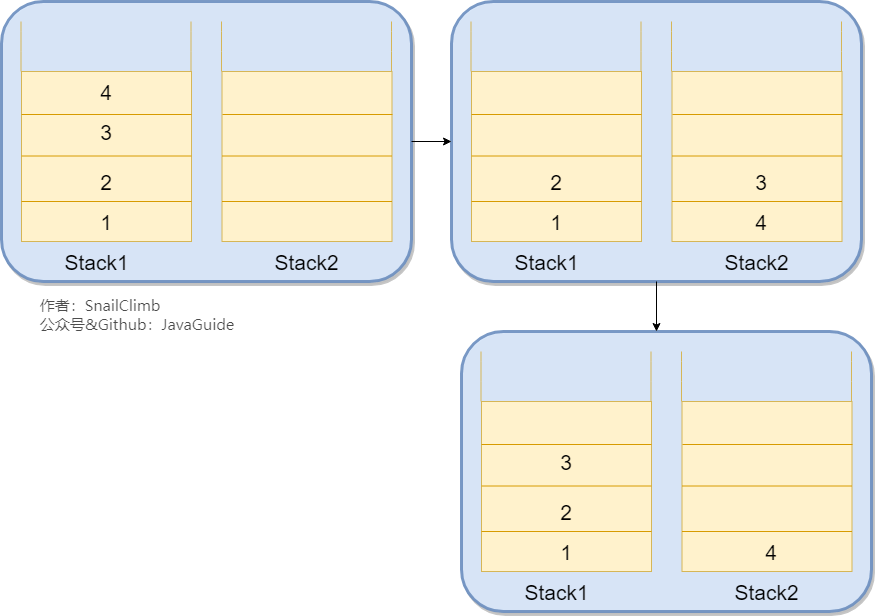
我们只需要使用两个栈(Stack1 和 Stack2)和就能实现这个功能。比如你按顺序查看了 1,2,3,4 这四个页面,我们依次把 1,2,3,4 这四个页面压入 Stack1 中。当你想回头看 2 这个页面的时候,你点击回退按钮,我们依次把 4,3 这两个页面从 Stack1 弹出,然后压入 Stack2 中。假如你又想回到页面 3,你点击前进按钮,我们将 3 页面从 Stack2 弹出,然后压入到 Stack1 中。示例图如下:
#### 3.2.2. 检查符号是否成对出现
> 给定一个只包括 `'('`,`')'`,`'{'`,`'}'`,`'['`,`']'` 的字符串,判断该字符串是否有效。
>
> 有效字符串需满足:
>
> 1. 左括号必须用相同类型的右括号闭合。
> 2. 左括号必须以正确的顺序闭合。
>
> 比如 "()"、"()[]{}"、"{[]}" 都是有效字符串,而 "(]" 、"([)]" 则不是。
这个问题实际是 Leetcode 的一道题目,我们可以利用栈 `Stack` 来解决这个问题。
1. 首先我们将括号间的对应规则存放在 `Map` 中,这一点应该毋容置疑;
2. 创建一个栈。遍历字符串,如果字符是左括号就直接加入`stack`中,否则将`stack` 的栈顶元素与这个括号做比较,如果不相等就直接返回 false。遍历结束,如果`stack`为空,返回 `true`。
```java
public boolean isValid(String s){
// 括号之间的对应规则
HashMap<Character, Character> mappings = new HashMap<Character, Character>();
mappings.put(')', '(');
mappings.put('}', '{');
mappings.put(']', '[');
Stack<Character> stack = new Stack<Character>();
char[] chars = s.toCharArray();
for (int i = 0; i < chars.length; i++) {
if (mappings.containsKey(chars[i])) {
char topElement = stack.empty() ? '#' : stack.pop();
if (topElement != mappings.get(chars[i])) {
return false;
}
} else {
stack.push(chars[i]);
}
}
return stack.isEmpty();
}
```
#### 3.2.3. 反转字符串
将字符串中的每个字符先入栈再出栈就可以了。
#### 3.2.4. 维护函数调用
最后一个被调用的函数必须先完成执行,符合栈的 **后进先出(LIFO, Last In First Out)** 特性。
### 3.3. 栈的实现
栈既可以通过数组实现,也可以通过链表来实现。不管基于数组还是链表,入栈、出栈的时间复杂度都为 O(1)。
下面我们使用数组来实现一个栈,并且这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。
> 提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用`Arrays.copyOf()`进行扩容;
```java
public class MyStack {
private int[] storage;//存放栈中元素的数组
private int capacity;//栈的容量
private int count;//栈中元素数量
private static final int GROW_FACTOR = 2;
//不带初始容量的构造方法。默认容量为8
public MyStack() {
this.capacity = 8;
this.storage=new int[8];
this.count = 0;
}
//带初始容量的构造方法
public MyStack(int initialCapacity) {
if (initialCapacity < 1)
throw new IllegalArgumentException("Capacity too small.");
this.capacity = initialCapacity;
this.storage = new int[initialCapacity];
this.count = 0;
}
//入栈
public void push(int value) {
if (count == capacity) {
ensureCapacity();
}
storage[count++] = value;
}
//确保容量大小
private void ensureCapacity() {
int newCapacity = capacity * GROW_FACTOR;
storage = Arrays.copyOf(storage, newCapacity);
capacity = newCapacity;
}
//返回栈顶元素并出栈
private int pop() {
if (count == 0)
throw new IllegalArgumentException("Stack is empty.");
count--;
return storage[count];
}
//返回栈顶元素不出栈
private int peek() {
if (count == 0){
throw new IllegalArgumentException("Stack is empty.");
}else {
return storage[count-1];
}
}
//判断栈是否为空
private boolean isEmpty() {
return count == 0;
}
//返回栈中元素的个数
private int size() {
return count;
}
}
```
验证
```java
MyStack myStack = new MyStack(3);
myStack.push(1);
myStack.push(2);
myStack.push(3);
myStack.push(4);
myStack.push(5);
myStack.push(6);
myStack.push(7);
myStack.push(8);
System.out.println(myStack.peek());//8
System.out.println(myStack.size());//8
for (int i = 0; i < 8; i++) {
System.out.println(myStack.pop());
}
System.out.println(myStack.isEmpty());//true
myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
```
## 4. 队列
### 4.1. 队列简介
**队列** 是 **先进先出( FIFO,First In, First Out)** 的线性表。在具体应用中通常用链表或者数组来实现,用数组实现的队列叫作 **顺序队列** ,用链表实现的队列叫作 **链式队列** 。**队列只允许在后端(rear)进行插入操作也就是 入队 enqueue,在前端(front)进行删除操作也就是出队 dequeue**
队列的操作方式和堆栈类似,唯一的区别在于队列只允许新数据在后端进行添加。
```java
假设队列中有n个元素。
访问:O(n)//最坏情况
插入删除:O(1)//后端插入前端删除元素
```

### 4.2. 队列分类
#### 4.2.1. 单队列
单队列就是常见的队列, 每次添加元素时,都是添加到队尾。单队列又分为 **顺序队列(数组实现)** 和 **链式队列(链表实现)**。
**顺序队列存在“假溢出”的问题也就是明明有位置却不能添加的情况。**
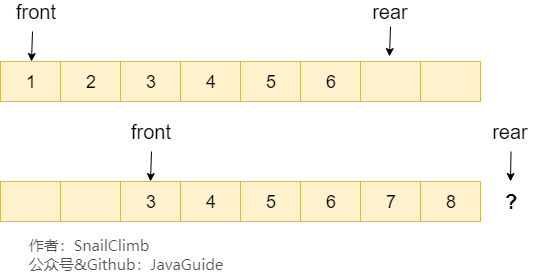
假设下图是一个顺序队列,我们将前两个元素 1,2 出队,并入队两个元素 7,8。当进行入队、出队操作的时候,front 和 rear 都会持续往后移动,当 rear 移动到最后的时候,我们无法再往队列中添加数据,即使数组中还有空余空间,这种现象就是 **”假溢出“** 。除了假溢出问题之外,如下图所示,当添加元素 8 的时候,rear 指针移动到数组之外(越界)。
> 为了避免当只有一个元素的时候,队头和队尾重合使处理变得麻烦,所以引入两个指针,front 指针指向对头元素,rear 指针指向队列最后一个元素的下一个位置,这样当 front 等于 rear 时,此队列不是还剩一个元素,而是空队列。——From 《大话数据结构》
#### 4.2.2. 循环队列
循环队列可以解决顺序队列的假溢出和越界问题。解决办法就是:从头开始,这样也就会形成头尾相接的循环,这也就是循环队列名字的由来。
还是用上面的图,我们将 rear 指针指向数组下标为 0 的位置就不会有越界问题了。当我们再向队列中添加元素的时候, rear 向后移动。
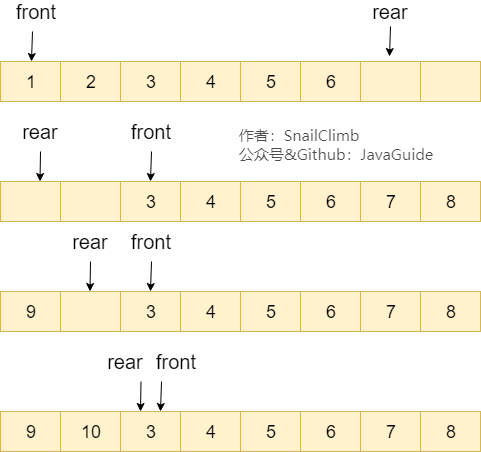
顺序队列中,我们说 `front==rear` 的时候队列为空,循环队列中则不一样,也可能为满,如上图所示。解决办法有两种:
1. 可以设置一个标志变量 `flag`,当 `front==rear` 并且 `flag=0` 的时候队列为空,当`front==rear` 并且 `flag=1` 的时候队列为满。
2. 队列为空的时候就是 `front==rear` ,队列满的时候,我们保证数组还有一个空闲的位置,rear 就指向这个空闲位置,如下图所示,那么现在判断队列是否为满的条件就是: `(rear+1) % QueueSize= front` 。

### 4.3. 常见应用场景
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如 :`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
- Linux 内核进程队列(按优先级排队)
- 现实生活中的派对,播放器上的播放列表;
- 消息队列
- 等等......
- 一.JVM
- 1.1 java代码是怎么运行的
- 1.2 JVM的内存区域
- 1.3 JVM运行时内存
- 1.4 JVM内存分配策略
- 1.5 JVM类加载机制与对象的生命周期
- 1.6 常用的垃圾回收算法
- 1.7 JVM垃圾收集器
- 1.8 CMS垃圾收集器
- 1.9 G1垃圾收集器
- 2.面试相关文章
- 2.1 可能是把Java内存区域讲得最清楚的一篇文章
- 2.0 GC调优参数
- 2.1GC排查系列
- 2.2 内存泄漏和内存溢出
- 2.2.3 深入理解JVM-hotspot虚拟机对象探秘
- 1.10 并发的可达性分析相关问题
- 二.Java集合架构
- 1.ArrayList深入源码分析
- 2.Vector深入源码分析
- 3.LinkedList深入源码分析
- 4.HashMap深入源码分析
- 5.ConcurrentHashMap深入源码分析
- 6.HashSet,LinkedHashSet 和 LinkedHashMap
- 7.容器中的设计模式
- 8.集合架构之面试指南
- 9.TreeSet和TreeMap
- 三.Java基础
- 1.基础概念
- 1.1 Java程序初始化的顺序是怎么样的
- 1.2 Java和C++的区别
- 1.3 反射
- 1.4 注解
- 1.5 泛型
- 1.6 字节与字符的区别以及访问修饰符
- 1.7 深拷贝与浅拷贝
- 1.8 字符串常量池
- 2.面向对象
- 3.关键字
- 4.基本数据类型与运算
- 5.字符串与数组
- 6.异常处理
- 7.Object 通用方法
- 8.Java8
- 8.1 Java 8 Tutorial
- 8.2 Java 8 数据流(Stream)
- 8.3 Java 8 并发教程:线程和执行器
- 8.4 Java 8 并发教程:同步和锁
- 8.5 Java 8 并发教程:原子变量和 ConcurrentMap
- 8.6 Java 8 API 示例:字符串、数值、算术和文件
- 8.7 在 Java 8 中避免 Null 检查
- 8.8 使用 Intellij IDEA 解决 Java 8 的数据流问题
- 四.Java 并发编程
- 1.线程的实现/创建
- 2.线程生命周期/状态转换
- 3.线程池
- 4.线程中的协作、中断
- 5.Java锁
- 5.1 乐观锁、悲观锁和自旋锁
- 5.2 Synchronized
- 5.3 ReentrantLock
- 5.4 公平锁和非公平锁
- 5.3.1 说说ReentrantLock的实现原理,以及ReentrantLock的核心源码是如何实现的?
- 5.5 锁优化和升级
- 6.多线程的上下文切换
- 7.死锁的产生和解决
- 8.J.U.C(java.util.concurrent)
- 0.简化版(快速复习用)
- 9.锁优化
- 10.Java 内存模型(JMM)
- 11.ThreadLocal详解
- 12 CAS
- 13.AQS
- 0.ArrayBlockingQueue和LinkedBlockingQueue的实现原理
- 1.DelayQueue的实现原理
- 14.Thread.join()实现原理
- 15.PriorityQueue 的特性和原理
- 16.CyclicBarrier的实际使用场景
- 五.Java I/O NIO
- 1.I/O模型简述
- 2.Java NIO之缓冲区
- 3.JAVA NIO之文件通道
- 4.Java NIO之套接字通道
- 5.Java NIO之选择器
- 6.基于 Java NIO 实现简单的 HTTP 服务器
- 7.BIO-NIO-AIO
- 8.netty(一)
- 9.NIO面试题
- 六.Java设计模式
- 1.单例模式
- 2.策略模式
- 3.模板方法
- 4.适配器模式
- 5.简单工厂
- 6.门面模式
- 7.代理模式
- 七.数据结构和算法
- 1.什么是红黑树
- 2.二叉树
- 2.1 二叉树的前序、中序、后序遍历
- 3.排序算法汇总
- 4.java实现链表及链表的重用操作
- 4.1算法题-链表反转
- 5.图的概述
- 6.常见的几道字符串算法题
- 7.几道常见的链表算法题
- 8.leetcode常见算法题1
- 9.LRU缓存策略
- 10.二进制及位运算
- 10.1.二进制和十进制转换
- 10.2.位运算
- 11.常见链表算法题
- 12.算法好文推荐
- 13.跳表
- 八.Spring 全家桶
- 1.Spring IOC
- 2.Spring AOP
- 3.Spring 事务管理
- 4.SpringMVC 运行流程和手动实现
- 0.Spring 核心技术
- 5.spring如何解决循环依赖问题
- 6.springboot自动装配原理
- 7.Spring中的循环依赖解决机制中,为什么要三级缓存,用二级缓存不够吗
- 8.beanFactory和factoryBean有什么区别
- 九.数据库
- 1.mybatis
- 1.1 MyBatis-# 与 $ 区别以及 sql 预编译
- Mybatis系列1-Configuration
- Mybatis系列2-SQL执行过程
- Mybatis系列3-之SqlSession
- Mybatis系列4-之Executor
- Mybatis系列5-StatementHandler
- Mybatis系列6-MappedStatement
- Mybatis系列7-参数设置揭秘(ParameterHandler)
- Mybatis系列8-缓存机制
- 2.浅谈聚簇索引和非聚簇索引的区别
- 3.mysql 证明为什么用limit时,offset很大会影响性能
- 4.MySQL中的索引
- 5.数据库索引2
- 6.面试题收集
- 7.MySQL行锁、表锁、间隙锁详解
- 8.数据库MVCC详解
- 9.一条SQL查询语句是如何执行的
- 10.MySQL 的 crash-safe 原理解析
- 11.MySQL 性能优化神器 Explain 使用分析
- 12.mysql中,一条update语句执行的过程是怎么样的?期间用到了mysql的哪些log,分别有什么作用
- 十.Redis
- 0.快速复习回顾Redis
- 1.通俗易懂的Redis数据结构基础教程
- 2.分布式锁(一)
- 3.分布式锁(二)
- 4.延时队列
- 5.位图Bitmaps
- 6.Bitmaps(位图)的使用
- 7.Scan
- 8.redis缓存雪崩、缓存击穿、缓存穿透
- 9.Redis为什么是单线程、及高并发快的3大原因详解
- 10.布隆过滤器你值得拥有的开发利器
- 11.Redis哨兵、复制、集群的设计原理与区别
- 12.redis的IO多路复用
- 13.相关redis面试题
- 14.redis集群
- 十一.中间件
- 1.RabbitMQ
- 1.1 RabbitMQ实战,hello world
- 1.2 RabbitMQ 实战,工作队列
- 1.3 RabbitMQ 实战, 发布订阅
- 1.4 RabbitMQ 实战,路由
- 1.5 RabbitMQ 实战,主题
- 1.6 Spring AMQP 的 AMQP 抽象
- 1.7 Spring AMQP 实战 – 整合 RabbitMQ 发送邮件
- 1.8 RabbitMQ 的消息持久化与 Spring AMQP 的实现剖析
- 1.9 RabbitMQ必备核心知识
- 2.RocketMQ 的几个简单问题与答案
- 2.Kafka
- 2.1 kafka 基础概念和术语
- 2.2 Kafka的重平衡(Rebalance)
- 2.3.kafka日志机制
- 2.4 kafka是pull还是push的方式传递消息的?
- 2.5 Kafka的数据处理流程
- 2.6 Kafka的脑裂预防和处理机制
- 2.7 Kafka中partition副本的Leader选举机制
- 2.8 如果Leader挂了的时候,follower没来得及同步,是否会出现数据不一致
- 2.9 kafka的partition副本是否会出现脑裂情况
- 十二.Zookeeper
- 0.什么是Zookeeper(漫画)
- 1.使用docker安装Zookeeper伪集群
- 3.ZooKeeper-Plus
- 4.zk实现分布式锁
- 5.ZooKeeper之Watcher机制
- 6.Zookeeper之选举及数据一致性
- 十三.计算机网络
- 1.进制转换:二进制、八进制、十六进制、十进制之间的转换
- 2.位运算
- 3.计算机网络面试题汇总1
- 十四.Docker
- 100.面试题收集合集
- 1.美团面试常见问题总结
- 2.b站部分面试题
- 3.比心面试题
- 4.腾讯面试题
- 5.哈罗部分面试
- 6.笔记
- 十五.Storm
- 1.Storm和流处理简介
- 2.Storm 核心概念详解
- 3.Storm 单机版本环境搭建
- 4.Storm 集群环境搭建
- 5.Storm 编程模型详解
- 6.Storm 项目三种打包方式对比分析
- 7.Storm 集成 Redis 详解
- 8.Storm 集成 HDFS 和 HBase
- 9.Storm 集成 Kafka
- 十六.Elasticsearch
- 1.初识ElasticSearch
- 2.文档基本CRUD、集群健康检查
- 3.shard&replica
- 4.document核心元数据解析及ES的并发控制
- 5.document的批量操作及数据路由原理
- 6.倒排索引
- 十七.分布式相关
- 1.分布式事务解决方案一网打尽
- 2.关于xxx怎么保证高可用的问题
- 3.一致性hash原理与实现
- 4.微服务注册中心 Nacos 比 Eureka的优势
- 5.Raft 协议算法
- 6.为什么微服务架构中需要网关
- 0.CAP与BASE理论
- 十八.Dubbo
- 1.快速掌握Dubbo常规应用
- 2.Dubbo应用进阶
- 3.Dubbo调用模块详解
- 4.Dubbo调用模块源码分析
- 6.Dubbo协议模块