在准备数据库以前,我们根据原型图抽像出`teacher`表如下:
| 字段 | 类型 | 主外键 | 备注 |
|---- |----| ----| ---- |
| id | bigint un | p(主键) | 自增 |
| name | varchar(255) | | 姓名 |
| username | varchar(255) | | 用户名 |
| email | varchar(255) | | 邮箱 |
| sex | bit(1) | | 性别 |
| create_time | bigint un | | 创建时间 |
| update_time | bigint un | | 更新时间 |
# 数据库
数据库我们仍然采用免费的`mysql`,版本选择常用的`5.7`。获取该版本的方式有很多,比如我们可以通过官方来获取,也可以通过下载一些集成的开发工具包比如`XAMPP`,`PHPStudy`或者使用`docker`来获取它。
每个学习的阶段都有学习的重点,本阶段我们的重点并不是掌握如何来安装`mysql`,所以如果你还不是`docker`用户,那么推荐安装[xampp](https://sourceforge.net/projects/xampp/files/)。
## docker环境
**注意:** 如果你还没有使用过的`docker`及`docker-compose`,请直接略过本小节。本小节的作用同`xampp`一样,也是在安装`mysql`。
如果你是`docker` 用户,可以使用以下的配置文件来达到与教程中的版本完全统一。
Dockerfile
```
FROM registry.cn-beijing.aliyuncs.com/mengyunzhi/mysql:5.7
```
docker-compose.yml
```
# 版本号
version: '3'
# 定义服务
services:
mysql57:
build:
context: ./
image: mysql:5.7
volumes:
- ./custom.cnf:/etc/mysql/conf.d/custom.cnf
- ./db:/var/lib/mysql
ports:
- "3307:3306"
environment:
- MYSQL_USER=root
- MYSQL_PASSWORD=
- MYSQL_ALLOW_EMPTY_PASSWORD=true
```
custom.cnf
```
[mysqld]
character-set-server = utf8
collation-server = utf8_unicode_ci
skip-character-set-client-handshake
```
相对位置如下:
```
panjiedeMac-Pro:mysql5.7 panjie$ tree -L 1
.
├── Dockerfile
├── custom.cnf
├── db
└── docker-compose.yml
1 directory, 3 files
```
>[info] `mysql`的版本号最低为5.7,请勿尝试5.6及以下的数据库。
# 数据库管理软件
数据库管理,我们仍然使用`navicat-for-mysql`这款国人开发的优秀数据库管理软件。产品地址:[https://www.navicat.com.cn/products/navicat-for-mysql](https://www.navicat.com.cn/products/navicat-for-mysql),点击右上角的`试用`按钮来到下载界面,其为普通用户提供了14天的试用期。如果你并不认同它的收费模式,还有很多个免费的数据库管理软件,比如:[workbench](http://dev.mysql.com/downloads/workbench/)、[Sequel Pro](http://www.sequelpro.com/)、[HeidiSQL](http://www.heidisql.com/)、[phpmyadmin](http://www.phpmyadmin.net/home_page/)、[dbForge Studio Express](http://www.devart.com/dbforge/mysql/studio/)、[DBTools Manager](http://www.dbtools.com.br/EN/dbmanagerpro/)或者[MyDB Studio](http://www.mydb-studio.com/)。
# 数据库初始化
> 传送门:[启动xampp中的mysql](https://www.kancloud.cn/yunzhiclub/thinkphp5guide/163808)、[使用navicat连接数据数](https://www.kancloud.cn/yunzhiclub/thinkphp5guide/165009)
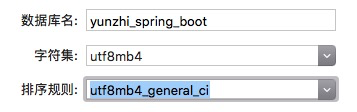
新建数据库名:`yunzhi_spring_boot`,字符设置为`utf8mb4`,默认排序方式选择`utf8mb4_general_ci`。
然后执行执行以下`sql`语句来达到快速建表的目的。
```sql
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for teacher
-- ----------------------------
DROP TABLE IF EXISTS `teacher`;
CREATE TABLE `teacher` (
`id` bigint(11) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT '' COMMENT '姓名',
`sex` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '0男,1女',
`username` varchar(255) NOT NULL COMMENT '用户名',
`email` varchar(255) DEFAULT '' COMMENT '邮箱',
`create_time` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_time` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`),
UNIQUE KEY `nx1HkMqiUveGnJz5lHE7mEcFI5WVew3iXbv3HCwF` (`username`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
-- ----------------------------
-- Records of teacher
-- ----------------------------
BEGIN;
INSERT INTO `teacher` VALUES (1, '张三', 1, 'zhangsan', 'zhangsan@mail.com', 1569721598000, 1569721598000);
INSERT INTO `teacher` VALUES (2, '李四', 0, 'lisi', 'lisi@yunzhi.club', 1569721598000, 1569721598000);
COMMIT;
SET FOREIGN_KEY_CHECKS = 1;
```
成功执行后,打开数据表管理,刷新后能看到`teacher`表说明执行成功。

# 本节小测
无
## 上节答案
规律一:方法➊➌➎➏同步,必然顺序执行。而➊➌➋➍➏➎去除异步➋➍后,为:➊➌➏➎,故➊➌➋➍➏➎错误。
规律二:异步方法由同步方法触发,所以➋必然晚于➊执行,➍必然晚于➌执行,故➊➋➍➌➎➏错误。
# 延伸阅读
以下内容需要一定的数据库知识,为选学内容。对该内容的学习有助于更好的掌握一些基础的知识点,它们可能是面试中的考点,也可能是你心中的疑点。慢慢的越来越多的弄懂这些,你会有一种一通百通的畅快感。如果没弄懂,那则是本教程书写水平的问题。是否掌握该问题不会影响你对教程后续章节的学习。
## 解读sql语句
```sql
SET NAMES utf8mb4; ➊
SET FOREIGN_KEY_CHECKS = 0; ➋
-- ---------------------------- ➌
-- Table structure for teacher ➌
-- ---------------------------- ➌
DROP TABLE IF EXISTS `teacher`; ➍
CREATE TABLE `teacher` ( ➎
`id` bigint(11) unsigned NOT NULL AUTO_INCREMENT, ➏
`name` varchar(255) DEFAULT '' COMMENT '姓名', ➐
`sex` tinyint(1) unsigned NOT NULL DEFAULT '0' COMMENT '0男,1女',
`username` varchar(255) NOT NULL COMMENT '用户名',
`email` varchar(255) DEFAULT '' COMMENT '邮箱',
`create_time` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT '创建时间',
`update_time` bigint(11) unsigned NOT NULL DEFAULT '0' COMMENT '更新时间',
PRIMARY KEY (`id`), ➑
UNIQUE KEY `nx1HkMqiUveGnJz5lHE7mEcFI5WVew3iXbv3HCwF` (`username`) USING BTREE ➒
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4; ➓
-- ---------------------------- ➌
-- Records of teacher ➌
-- ---------------------------- ➌
BEGIN; ➊➋
INSERT INTO `teacher` VALUES (1, '张三', 0, 'zhangsan', 'zhangsan@mail.com', 1569721598000, 1569721598000); ➊➌
INSERT INTO `teacher` VALUES (2, '李四', 0, 'lisi', 'lisi@yunzhi.club', 1569721598000, 1569721598000);
COMMIT; ➊➍
SET FOREIGN_KEY_CHECKS = 1; ➊➎
```
➊ 设置编码为`utf8mb4`
➋ 关闭外键检查
➌ 注释内容
➍ 如果表存在,则将老表删除
➎ 创建数据表
➏ 创建int类型字段,显示长度为11,无符号数,不允许为null,自动增加字段
➐ 创建varchar可变字长字符串类型字段,最大长度255
➑ 声明主键
➒ 在username字段上设置UNIQUE索引
➓ 设置引擎为InnoDB,自增值为3,默认字符编码为`utf8mb4`
➊➋ 开启事务
➊➌ 插入数据
➊➍ 提交事务
➊➎ 开启外键检查
## 字符编码
做个小实验,执行以下语句建立一张TEST表。
```sql
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for test
-- ----------------------------
DROP TABLE IF EXISTS `test`;
CREATE TABLE `test` (
`name_ascii` varchar(255) CHARACTER SET ascii DEFAULT NULL,
`name_gb2312` varchar(255) CHARACTER SET gb2312 DEFAULT NULL,
`name_utf8` varchar(255) CHARACTER SET utf8 DEFAULT NULL,
`name_utf8mb4` varchar(255) CHARACTER SET utf8mb4 DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
SET FOREIGN_KEY_CHECKS = 1;
```
执行上述代码得到一张数据表,该表中存在4个字段,除了字符编码不同外,其它的属性均相同。
>[warning] 使用navicate打开此表时,会得到一个没有主键的警告,该警告并不影响本次测试,请忽略。
接下来,我依次尝试向以上4字字段中输入以下4个字符:
`a`、`梦`、`☂`、`𠜎`
➊ 输入`a`时,四个字段全部可以正常保存。
➋ 输入`梦`时,后三个字段是可以正常保存的,第一个字段`name_ascii`发生以下错误提示。

```
1366 - Incorrect string value: '\xE6\xA2\xA6' for column 'name_ascii' at row 1
错误代码1366 - 在第1行`name_ascii`的字段上发现了不正确的字符串数值:'\xE6\xA2\xA6'
```
➌ 输入`☂`时,后两个字段可以正常保存。

```
1366 - Incorrect string value: '\xE2\x98\x82' for column 'name_gb2312' at row 1
错误代码1366 - 在第1行`name_gb2312`的字段上发现了不正确的字符串数值:'\xE2\x98\x82'
```
➍ 输入`𠜎`时,只有最后一个字段可以正常保存。

```
1366 - Incorrect string value: '\xF0\xA0\x9C\x8E' for column 'name_utf8' at row 4
错误代码1366 - 在第1行`name_utf8`的字段上发现了不正确的字符串数值:'\xF0\xA0\x9C\x8E'
```
相同的文字,存入不同编码类型中的字段中,有的就会报错,有的就不会。这是为什么呢?
*****
下面我们共同简单地补一下基础知识。
笔者认为:**编码(Character encoding)** 本质上是:将一种数据形式转换成另外一种数据形式的方法。计算机本质上存的数据非`0`即`1`,也就是说我们是没有办法将除了01之外的东西直接存在计算机上的。这时候如果想把文字存在计算机中,就要将文字转换为01格式的二进制数。由于二进制数据在进行交流时不太符合人类固化的交互方式,所以在进行二进制交流的时候,为了更加友好服务于非程序员的广大用户群体,我们在交流二进制时往往会做两项处理:
1. 在适当的位置进行划分。
2. 将其转换为10进制或是16进制。
比如我们说某个IP地址是`192.168.0.1`,其实是在说某个IP地址是`11000000101010000000000000000001`。
此IP地址,经过两次处理的过程如下:
1. 在适当的位置进行划分 - `11000000 10101000 00000000 00000001`
2. 将其转换为10进制或是16进制。
```
11000000 10101000 00000000 00000001 =
2⁷ +2⁶ 2⁷ + 2⁵ 0 2⁰ =
128+64 128+32 0 1 =
192 168 0 1
```
这虽然对非程序员友好了,但对我们并不太友好。由于2进制与16进制天然的关系,程序员进行交流的时候,更喜欢用16进制来表示二进制。所以上述二制制如果用16进制来表示的话,转换方法如下:
```
1100 0000 1010 1000 0000 0000 0000 0001 =
8400 0000 8020 8000 0000 0000 0000 0001 =
12 0 10 8 0 0 0 1 =
c 0 a 8 0 0 0 1 =
c0 a8 00 01
```
在转换过程中的第二行`8400`并不该读成`8千4百`,而应该读成`8加4加0加0`,这也是`8421码`的由来,当对应的二制进位为`1`时,我们在下方对应写入`8421码`的权重。反之亦然,由于`a8`\= `10 8` = `8+2+0+0 8+0+0+0` = `1100 1000`,所以可能很轻松的转换成二进制数。
>[success] 我国早在宋代的时候,就已经使用了16两为一斤计数方法。成语半斤八两往往指不相上下。这是因为在当时一斤是16两,那么半斤当然就是8两了。
*****
有了以上知识的铺垫,再理解编码就轻松一些了。字符编码是一种将字符映射为二进制的方法,只所以要映射为二进制,是由于计算机只能识别二进制。ascii编码是针对英文编码的方法,此编码每个英文字符都对应一个不大于255(1111 1111)的二进制数。所以能够表示的字符最多有256(0-255)个,比如我们熟悉的`a`,它对应的ascii编码为`97(0110 0001)`。也就是说:当我们使用该编码像计算机存入`a`,最终计算机保存的数据是`0110 0001`。在比如`b`,它对应的ascii编码为`98(0110 0010)`。在该编码下,每个字符都占用8个二进制位。8个二进制
位等于1个字节。所以我们又常说ascii中,每个字符占用的空间是1个字节。
ascii编码占用了1个字节,可以表示256个不同的字符,这在英文系统下,已经足够用了。但我们中国汉字博大精深,256个字符根本就容不下。这时候就发明了一种可以容的下中文字符的编码`gb2312`,它占用了2个字节的空间,可以最多容纳2的16次方即65536个文字。
但随着全国化进程的推进,人们很快的发现了新问题:那就是各个国家的文字都有不同的编码,大家虽然都能够在自己的编码下HAPPY的不行,但发现如果去对方的天空下,就完全哑了。这就好像我只会说汉语,有一天把我扔到以英文为交流语言的国家一样。这时候`utf8`编码就产生了。`utf8`就是世界通用语言,这下大家都用这种语言交流,但没有了障碍。这时候2个字节就不够它用了,所以`utf8`用了3个字节,即24个二制位,最多容纳2的24次方即16777216个文字。一下子解决全世界所有语言的问题。然后大家把这个字典进行印刷,发布给了全球所有的计算机,世界语的问题终于得到解决了。
但实际应用总和理论开些玩笑,`utf8`用了一段时间后,我们突然发现:咦?我们博大精深的中文文字竟然还有没有被世界语涵盖的(我猜是忘 了,毕竟中国字那么多,新华字典也是人编的,落下几个太正常不过了),而且不止一两个再比如:𠜱 𠝹 𠱓 𠱸 𠲖 𠳏 𠳕 𠴕 𠵼 𠵿 𠸎 𠸏 𠹷 𠺝 𠺢 𠻗 𠻹 𠻺 𠼭 𠼮 𠽌 𠾴 𠾼 𠿪 𡁜 𡁯 𡁵 𡁶 𡁻 𡃁 𡃉 𡇙 𢃇 𢞵 𢫕 𢭃 𢯊 𢱑 𢱕 𢳂 𢴈 𢵌 𢵧 𢺳 𣲷 𤓓 𤶸 𤷪 𥄫 𦉘 𦟌 𦧲 𦧺 𧨾 𨅝 𨈇 𨋢 𨳊 𨳍 𨳒 𩶘。上面这些都没有。读到这,相信你已经猜到结果了,那就是出现了`utf8mb4`。该编码每个字符占用4个字节,最多容易2的32次方个字字符。
现在我们回顾下前面的错误:
```
1366 - Incorrect string value: '\xE6\xA2\xA6' for column 'name_ascii' at row 1
错误代码1366 - 在第1行`name_ascii`的字段上发现了不正确的字符串数值:'\xE6\xA2\xA6'
```
'\\xE6\\xA2\\xA6'代表 16进制下的E6 A2 A6,其本质上是个3个字节,长度为24的二进制数。而`name_ascii`的字符集是`ascii`,长度为8,此时想往里存入24位的数据,当然就会发生错误了。
`gb2312`的长度为16,那么为什么在存`梦`的时候,没报错呢?刚刚我们不是说`梦`的长度是24吗?这个是因为这样:我们从网上复制数据的时候,由于网页的编码格式是utf8。所以我们复制下去的`梦`本身就是个`utf-8`格式的,在剪切板中,存的它的值是`0xE6 0xA2 0xA6` [传送门](https://www.fileformat.info/info/unicode/char/68a6/index.htm)。数据在进行保存的时候,会尝试将复制过来的utf-8格式的字符先转成gb2312,然后再进行保存。梦字是可以转换成功的,所以实际上最后存的不是`0xE6 0xA2 0xA6`,而`0x34 0x56`[传送门](https://bianma.supfree.net/chaye.asp?id=68A6)。
但`☂`、`𠜎`,并没有存在于gb2312编码中,所以转换失败后尝试直接存剪切板中的二制数据,此数值长度分别是24位及32位,当然就报错了。教程中在存字符串时我们使用了更为宽泛的`utf8mb4`编码,以保证在存入特殊字符时,不发生错误。
## bigint(11)
todo: int(4),int(11),bigint(11),括号中的数字是什么意思呢,好像从来没有管过也没有受过影响 。
# 你可能遇到的问题
* [MySQL 5.6 建立数据表时出现1071错误,原因分析及解决办法](https://segmentfault.com/a/1190000020954608)
- 序言
- 第一章:Hello World
- 第一节:Angular准备工作
- 1 Node.js
- 2 npm
- 3 WebStorm
- 第二节:Hello Angular
- 第三节:Spring Boot准备工作
- 1 JDK
- 2 MAVEN
- 3 IDEA
- 第四节:Hello Spring Boot
- 1 Spring Initializr
- 2 Hello Spring Boot!
- 3 maven国内源配置
- 4 package与import
- 第五节:Hello Spring Boot + Angular
- 1 依赖注入【前】
- 2 HttpClient获取数据【前】
- 3 数据绑定【前】
- 4 回调函数【选学】
- 第二章 教师管理
- 第一节 数据库初始化
- 第二节 CRUD之R查数据
- 1 原型初始化【前】
- 2 连接数据库【后】
- 3 使用JDBC读取数据【后】
- 4 前后台对接
- 5 ng-if【前】
- 6 日期管道【前】
- 第三节 CRUD之C增数据
- 1 新建组件并映射路由【前】
- 2 模板驱动表单【前】
- 3 httpClient post请求【前】
- 4 保存数据【后】
- 5 组件间调用【前】
- 第四节 CRUD之U改数据
- 1 路由参数【前】
- 2 请求映射【后】
- 3 前后台对接【前】
- 4 更新数据【前】
- 5 更新某个教师【后】
- 6 路由器链接【前】
- 7 观察者模式【前】
- 第五节 CRUD之D删数据
- 1 绑定到用户输入事件【前】
- 2 删除某个教师【后】
- 第六节 代码重构
- 1 文件夹化【前】
- 2 优化交互体验【前】
- 3 相对与绝对地址【前】
- 第三章 班级管理
- 第一节 JPA初始化数据表
- 第二节 班级列表
- 1 新建模块【前】
- 2 初识单元测试【前】
- 3 初始化原型【前】
- 4 面向对象【前】
- 5 测试HTTP请求【前】
- 6 测试INPUT【前】
- 7 测试BUTTON【前】
- 8 @RequestParam【后】
- 9 Repository【后】
- 10 前后台对接【前】
- 第三节 新增班级
- 1 初始化【前】
- 2 响应式表单【前】
- 3 测试POST请求【前】
- 4 JPA插入数据【后】
- 5 单元测试【后】
- 6 惰性加载【前】
- 7 对接【前】
- 第四节 编辑班级
- 1 FormGroup【前】
- 2 x、[x]、{{x}}与(x)【前】
- 3 模拟路由服务【前】
- 4 测试间谍spy【前】
- 5 使用JPA更新数据【后】
- 6 分层开发【后】
- 7 前后台对接
- 8 深入imports【前】
- 9 深入exports【前】
- 第五节 选择教师组件
- 1 初始化【前】
- 2 动态数据绑定【前】
- 3 初识泛型
- 4 @Output()【前】
- 5 @Input()【前】
- 6 再识单元测试【前】
- 7 其它问题
- 第六节 删除班级
- 1 TDD【前】
- 2 TDD【后】
- 3 前后台对接
- 第四章 学生管理
- 第一节 引入Bootstrap【前】
- 第二节 NAV导航组件【前】
- 1 初始化
- 2 Bootstrap格式化
- 3 RouterLinkActive
- 第三节 footer组件【前】
- 第四节 欢迎界面【前】
- 第五节 新增学生
- 1 初始化【前】
- 2 选择班级组件【前】
- 3 复用选择组件【前】
- 4 完善功能【前】
- 5 MVC【前】
- 6 非NULL校验【后】
- 7 唯一性校验【后】
- 8 @PrePersist【后】
- 9 CM层开发【后】
- 10 集成测试
- 第六节 学生列表
- 1 分页【后】
- 2 HashMap与LinkedHashMap
- 3 初识综合查询【后】
- 4 综合查询进阶【后】
- 5 小试综合查询【后】
- 6 初始化【前】
- 7 M层【前】
- 8 单元测试与分页【前】
- 9 单选与多选【前】
- 10 集成测试
- 第七节 编辑学生
- 1 初始化【前】
- 2 嵌套组件测试【前】
- 3 功能开发【前】
- 4 JsonPath【后】
- 5 spyOn【后】
- 6 集成测试
- 7 @Input 异步传值【前】
- 8 值传递与引入传递
- 9 @PreUpdate【后】
- 10 表单验证【前】
- 第八节 删除学生
- 1 CSS选择器【前】
- 2 confirm【前】
- 3 功能开发与测试【后】
- 4 集成测试
- 5 定制提示框【前】
- 6 引入图标库【前】
- 第九节 集成测试
- 第五章 登录与注销
- 第一节:普通登录
- 1 原型【前】
- 2 功能设计【前】
- 3 功能设计【后】
- 4 应用登录组件【前】
- 5 注销【前】
- 6 保留登录状态【前】
- 第二节:你是谁
- 1 过滤器【后】
- 2 令牌机制【后】
- 3 装饰器模式【后】
- 4 拦截器【前】
- 5 RxJS操作符【前】
- 6 用户登录与注销【后】
- 7 个人中心【前】
- 8 拦截器【后】
- 9 集成测试
- 10 单例模式
- 第六章 课程管理
- 第一节 新增课程
- 1 初始化【前】
- 2 嵌套组件测试【前】
- 3 async管道【前】
- 4 优雅的测试【前】
- 5 功能开发【前】
- 6 实体监听器【后】
- 7 @ManyToMany【后】
- 8 集成测试【前】
- 9 异步验证器【前】
- 10 详解CORS【前】
- 第二节 课程列表
- 第三节 果断
- 1 初始化【前】
- 2 分页组件【前】
- 2 分页组件【前】
- 3 综合查询【前】
- 4 综合查询【后】
- 4 综合查询【后】
- 第节 班级列表
- 第节 教师列表
- 第节 编辑课程
- TODO返回机制【前】
- 4 弹出框组件【前】
- 5 多路由出口【前】
- 第节 删除课程
- 第七章 权限管理
- 第一节 AOP
- 总结
- 开发规范
- 备用