数据结构一向是找工作时的考点及难点,在此我们简单以实例来简单对HashMap及LinkHashMap进行说明。
# 前言(fei hua)
其实所有的数据结构最终都是在解决**取数**的问题,而如何能够按照要求要**取数**,则需要有一个良好的**存数**机制,现实生活中最典型的数据结构就是我们身边的图书馆了,图书馆那规则对图书进行编码,比如我们查询某本图书得到以下信息:
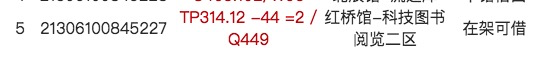
我们按此提示信息,来到红桥管阅览二区找到**分类号**TP314.12对应的图书区,然后在按该索引号的**字顺**逐渐的找到我们想借阅的书籍。只所以能够按上述的规则找到相关的书籍,是由于在进行图书上架时先对图片进行了分类、编码,然后按分类编码进行了相应的存放。这其实就是一种数据结构,数据结构规定了如果存数据,同时又按存数据的规则来规定了如何取数据。
回想一下第一次去图书馆的经历是非常痛苦的,虽然可以根据索引号来快速的获取分类号,但TP31X的图书真是太多了。按**字顺**索引的方式,很难由TP311(程序设计、软件工程)、TP312(程序语言、算法语言)等热门的书籍中快速找到我们想到的那本。
# HashMap
HashMap的出现,便很好的解决当前了问题。关于HashMap的文章google一搜一大把,具体的原理层面的就是不在这里重复讲了。在此,我们举个小例子来帮助大家来理解这个HashMap。
## 情景模拟
我们假设以下情景:
* [ ] 你有90张银行卡片,这些银行卡片的尾号是随机的
* [ ] 你有很多张小卡片,每张小卡片仅可记录1个两位数
* [ ] 你家中有100个可以存放银行卡片的储物格,每个储物格均存放了一张银行卡片和一张小卡片
* [ ] 对100个储物格进行编号,范围为0-99。
## 问题
你每天都需要随机的由支付定绑定的银行卡列表中找一张银行卡,进而去ATM机提现,那你如何能够快速的由储物格中找到这张卡片。
## 解决方案
HashMap是解决方案的一种,它的解决方案大体如下:
首先,拿出10个小卡片顺序排列(0-9号),并将每个储物格内内置一张小卡片:
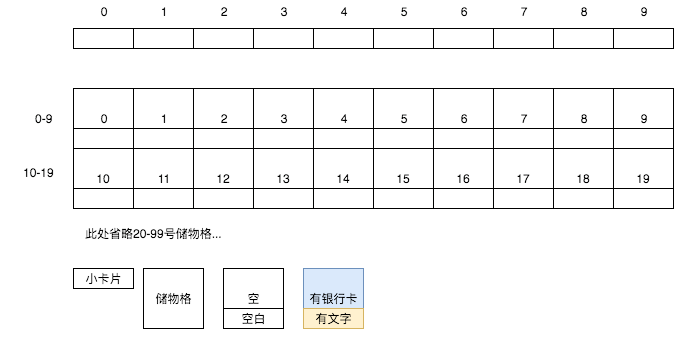
然后假设依次装入100张银行卡,前10张卡的卡号分别为:
```
xxxxxxxxx1025
xxxxxxxxx7842
xxxxxxxxx9863
xxxxxxxxx5625
xxxxxxxxx2324
xxxxxxxxx6532
xxxxxxxxx3699
xxxxxxxxx9845
xxxxxxxxx6242
```
### 存数据
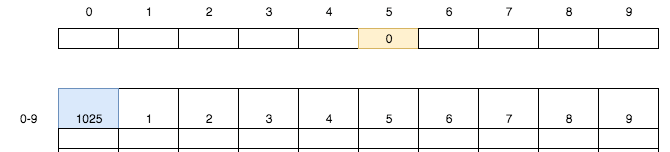
第银行卡102`5`装入`0`号储物格,同时将第`5`号小卡片的值设置为`0`
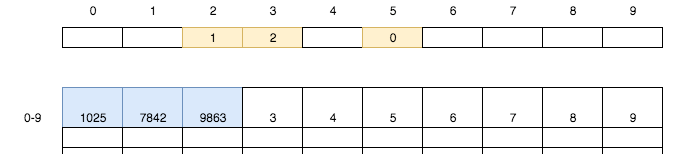
将银行卡784`2`装入`1`号储物格,同时将第`2`号小卡片的值设置为`1`;将银行卡986`3`装入第`2`号储物格,同时将第`3`号小卡片的值设置为`2`。
将银行卡562`5`装入第`3`号储物格。同时尝试将第`5`号小卡片的值设置为`3`:
* [ ] 1. 如果该小卡片空白,则写入`3`,程序终止
* [ ] 2. 否则获取小卡片上的值
* [ ] 3. 找到该值对应的储物格中的小卡片
* [ ] 4. 重复1
所以我们获取到了5号小卡片上的值0,来到了0号储物格并取出其小卡片,并写入3.
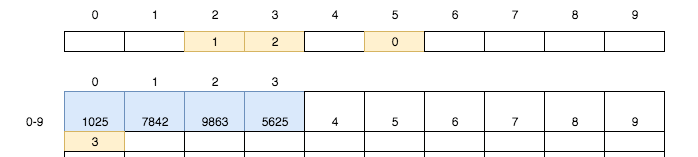
继续按上述规则存入2324、6532两张银行卡:
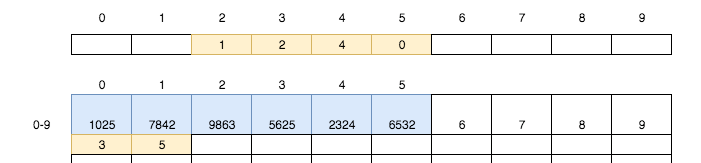
仔细的观察上图,我们好像发现了一个规律,那就是小卡片上记录的文字即是储物格的编号。如果将小卡片与储物格用颜色进行关联,则将得到下图:
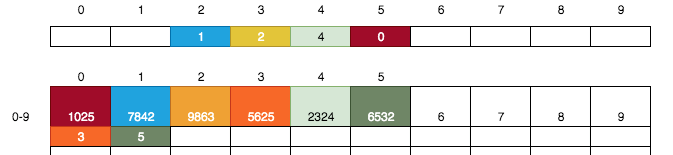
我们刚刚顺序的存放了几张银行卡,其实这并不是必须的,比如我们可以将下一张3699尾号的银行卡直接放到7号储物格中:
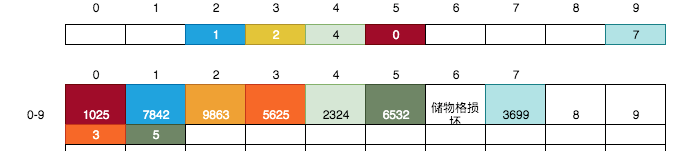
这完全没有任何问题,我们继续按上面的规则将9845放到第10号储物格(假设第8,9号储物格暂不可用)中:
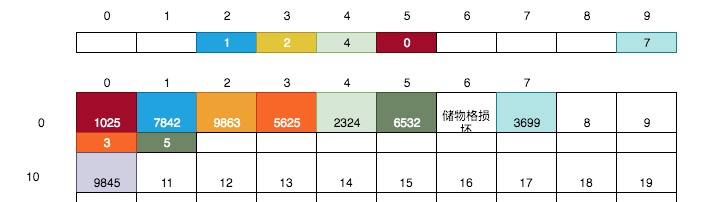
其尾号为5,则找第5号卡片,得到值0 -> 继续找第0号储物格,得到0号储物格的小卡片的值3 -> 继续找第3号储物格, 得到该储物格中的空白小卡片,于是将10写入到该卡片上。

> 最后一张银行卡,你来放吧。
### 取数据
数据存好了,取就简单了。假设我们要取7842的银行卡。
* 9842的尾号为2
* 找到第2号小卡片,获取值1
* 找到1号储物格,该银行卡即为我们想要的9842
假设我们要找9845号银行卡:
* 9845的尾号为5
* 找到第5号小卡,获取值0
* 找到第0号储物格,获取银行卡1025,不是我们要找的9845,则读取该储物盒中的小卡片的值3
* 找到第3号储物格,获取银行卡5825,不是我们要找的9845,则读取该储物盒中的小卡片的值10
* 找到第10号储物格,获取银行卡9845,返回。
假设我们要找9999号银行卡
* 9999的尾号为9
* 找到第9号小卡,获取值7
* 找到第7号储物格,获取银行卡3699,不是我们要找的9999,则读取该储物盒中的小卡片的值
* 该卡片无值,表明我们未存储尾号为9999的银行卡,返回null
以上存银行卡的过程,即是HaspMap的存值和取值过程,删除数据的过程也不复杂,主要是要考虑删除数据不能对历史的数据查询造成影响。比如我们想删除1025这个银行卡,则:
* [ ] 通过小卡片A找到该银行卡所在的储物格
* [ ] 获取该储物格的小卡片B
* [ ] 将小卡片B移到小卡片A的位置
* [ ] 清空该储物格(移除银行卡、放置新的小卡片)
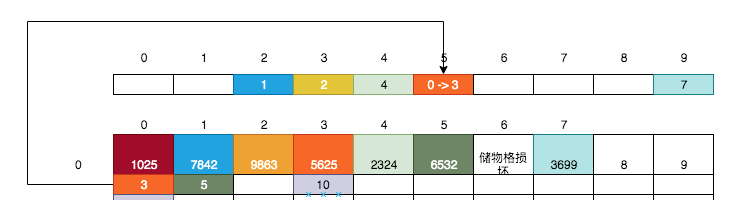
将小卡片B(数值为3)移到小卡片A(数值为0)的位置,清空0号储物格中后:
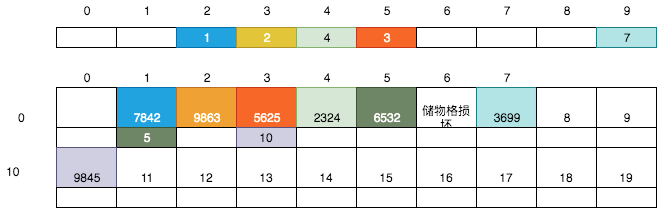
# 图的认读
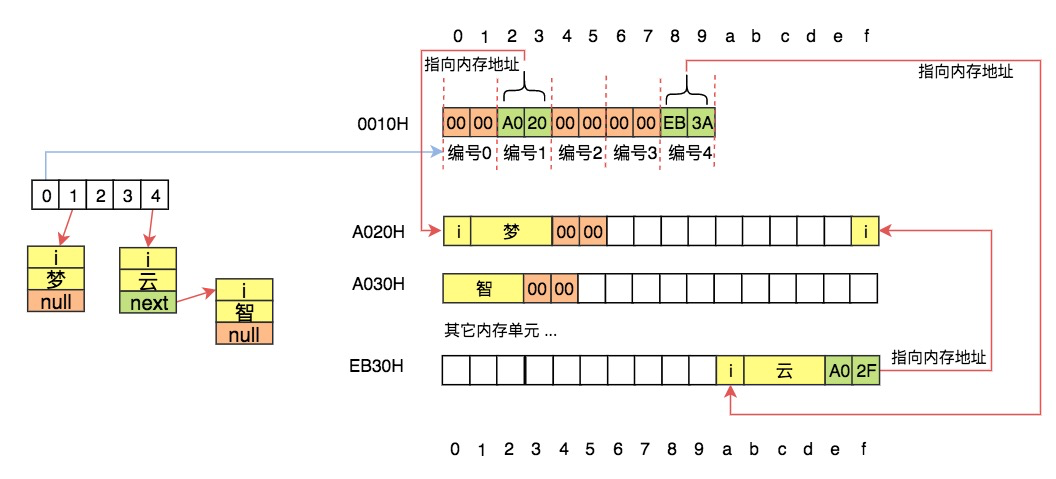
在计算机中,无论是小卡片还是储物格,对应的都是**内存**,内存是连续的存储空间,就像我们刚刚看到的连续的储物格。我们常说计算机是**内存**最小的单元是位bit,每位可以存储一个二进制0或1。对内存操作时,往往会把8位看做一个整体来进行集中操作,这是由于`位`的粒度实在是太小了,就像现实生活中我们无法购买一粒瓜子以及无法购法1ml的牛奶是一个道理。在计算机中,把8个位组成的连续存储单元称为1个字节,这便是内存单元的最小粒度,也是我们在学习相关的理论课时1Byte = 8bit的根本原因。前面我们学习过了字符的编码,经查询在UTF-8编码中`梦`的编码为:`0xE6 0xA2 0xA6 (e6a2a6)`;也学习过ascii编码,经查询`i`的编码为`0x69`。则在内存中是如下存储`i梦`这两个字符的:
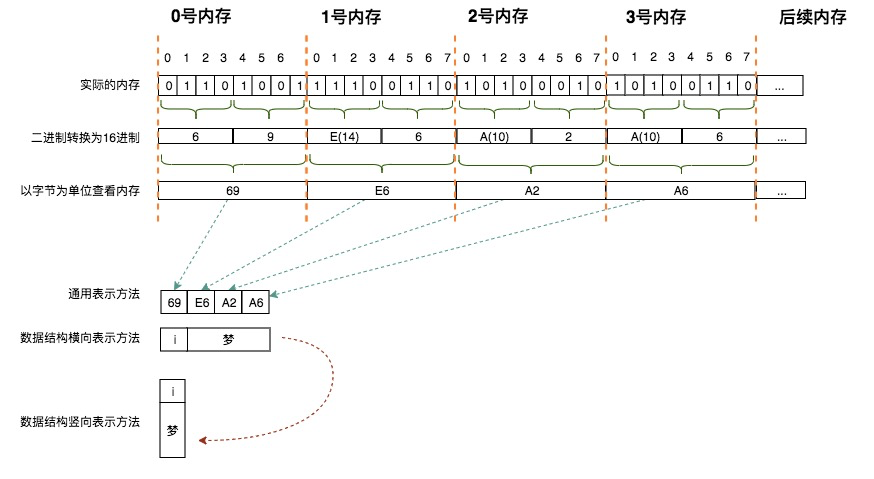
由于4个二进制(位)恰好可以用1个16进制来表示,所以为了易于交流、阅读,我们通常会将二进制转换为16进制。进而在一个内存单元中,便由8个二制进的位变为2个16进制的字符了。比如我们在手机中查看硬件信息(ios中请依次点击:通用 -> 关于本机),会发现无线局域网地址、蓝牙设置的信息。该信息即是用16进制来表示的二进制,比如我的手机无线局域网地址为:`80:82:D5:...`,每两位16进制为1组,这2个16进制共同表示了一个字节的内容;在比如我们进行IP地址设置时,假设设定值为:`192.168.0.1`,中间之所以用`.`进行分离,也是由于每个分隔的数字代表了一个字节,8个二进制(1个字节)在无符号数中的取值范围是0-255,所以当我们设置IP地址的相关参数时,最大值不会超出255,也就是16进制的FF,如果超出这个值,1个字节就放不下了,所以当我们尝试使用大于255的值设置IP地址的相关值时,操作系统会使用自己的错误提醒机制来提醒我们。
我们在计算机专业课的学习过程中,常常会看到这样表示内存:

每个内存单元均表示8个二进制数,即一个字节。在表示过程中,常用两个16进制数来表示:

内存是连续的存储空间,但由于印刷方便的原因,在进行一些内存展示的时候,我们无法在一行中将所有的内存单元一字排开。所以才采用了上面的展示方法,也就是说每行的最后一个内存单元与下一行的第一个内存单元实际上是邻居:
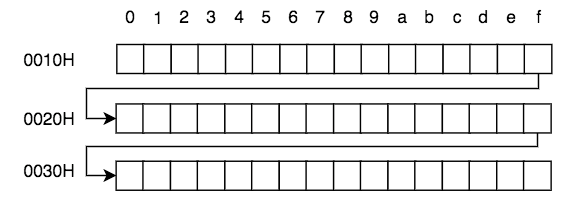
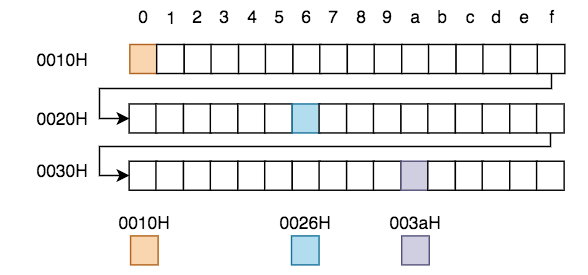
左侧与上侧的数字共同决定了某块内存单元的编号,此编号的最小值为0,最大为FFFFH(16位机)或FFFF FFFFH (32位机)或FFFF FFFF FFFF FFFFH(64位机)。在各种演示及图表中,我们更喜欢使用位数更少的16位机地址来做示例,16位机较32、64位机而言除了长度不同以外,其它的均相同。随便找3个内存单元,他们地址如下:
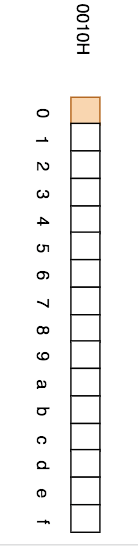
有部分图解中,也会用竖直的方式来表示内存:
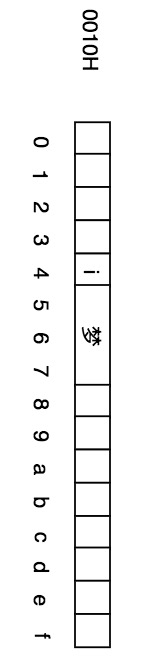
这与横向使用完全相同,只所以竖着用也是完全出于印刷的角度。如果使用此段内存的4-7号来存储`i梦`,则在数据结构中相应图表中,会如下表示:
## 计算机中的HASHMAP
有了前面看图表的基础知识,结合google再理解hashMap就不难了,由网上找到了一张原图如下:
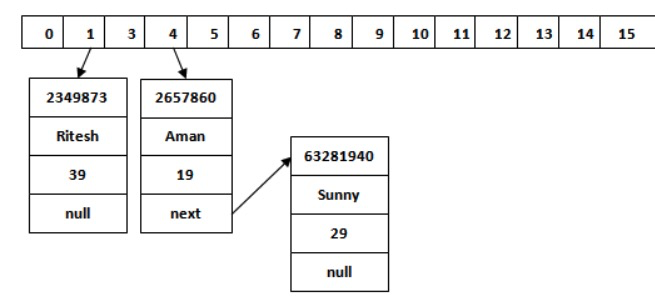
加入图解后:
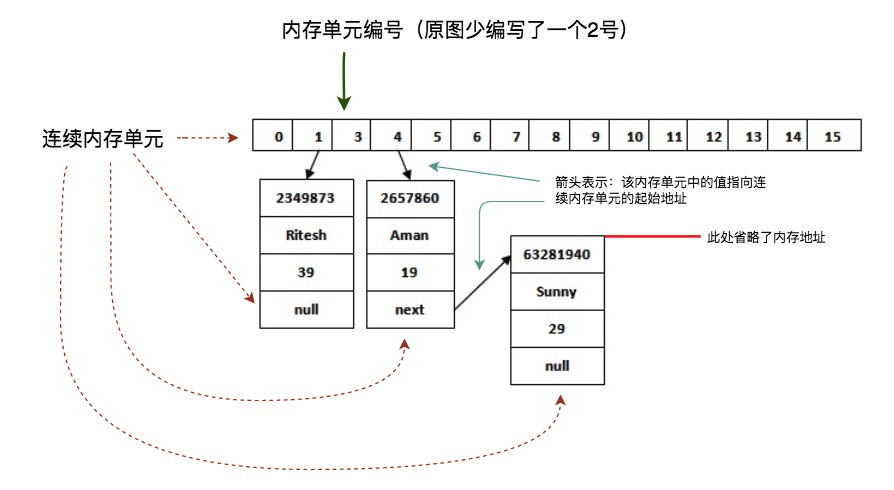
计算机的HashMap存数据与我们的在存储格中存银行卡大同小异,它大概经历这么4个步骤。
* [ ] 拿出16个小卡片(连续的内存单元)
* [ ] 随便找块连续内存,存对象(实际上为对象的引用)以及next小卡片,并记录该连续内存的**起始地址**。
* [ ] 获取存入对象的hash值(JVM提供,基于内存地址),比如获取到的值为2657860
* [ ] 使用对象的hash值与(16 - 1)相与,得到一个0 - 15之间的值,比如 `2657860 & (16-1) = 4`,结果为4
* [ ] 去4号卡片找值,该卡片如果无值,则将**起始地址**存入;如果有值,则按该值去找连续内存单元中的next;next无值,便存入**起始地址**,有值则继续向下找。
我们以16位机为例,在上图的基础上存入`i梦`、`i云`、`i智`:
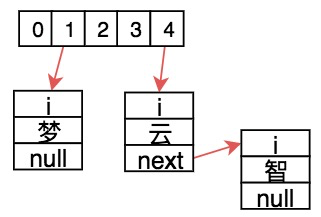
则表示实际在内存中如下进行存储:
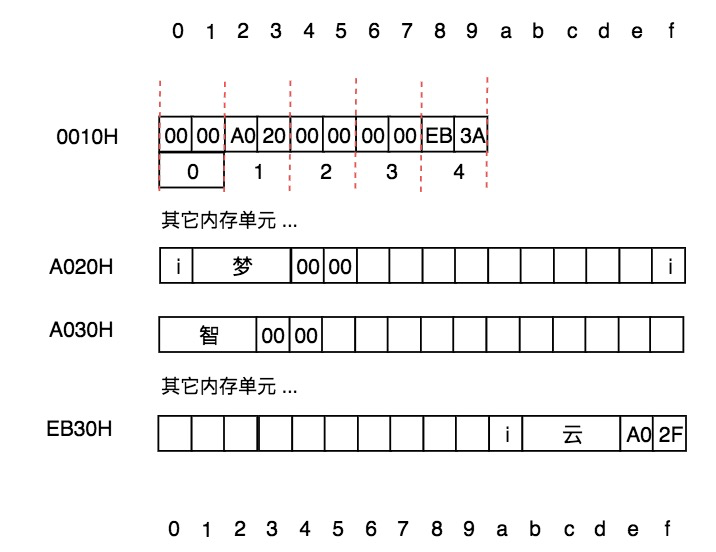
它们间的对应关系为:
# LinkedHashMap
LInkedHashMap结合了HashMap及双向链表,它牺牲了部分查询效率,多占用了一些内存空间,但解决了HashMap无序的特点。
> 在获取HaspMap中的全部数据时,它输出数据的顺序并不取决于输入数据的顺序。也就是说,同是一组数据输入HashMap,无论你的输入顺序是什么,最终循环获取HashMap中的值时,得到的输出顺序都是一致的。
## 基础数据结构
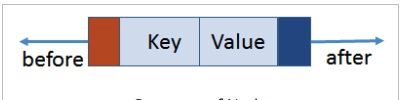
在储物格中又增加了一张卡片来记录上一条数据的位置。
* before 上一条数据的位置(连续内存存储起始位置)
* key、value两个数据项
* after 下一条数据的位置
## 第一次添加数据
`put(cbr250r, null)`,计算cbr250的hash值与15相与的值为10
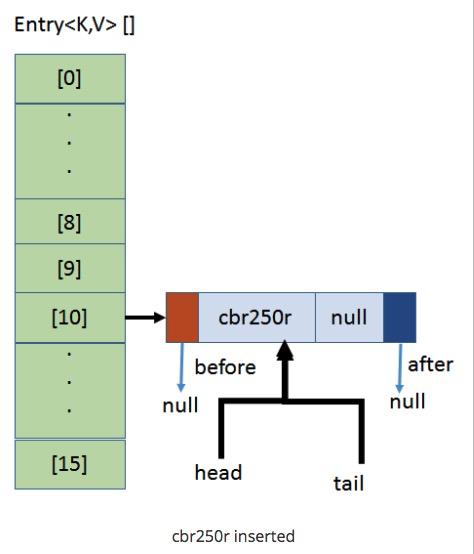
* 与HashMap相同,LinkHashMap先创建了大小为16的连续内存空间,并添加数据
* 增加了两个属性head与tail分别记录头与尾,并将这两个属性同时指向了该数据。
> 其实16这个数字并不准确,相对于8位机,它的大小就是16;但相对于16位机,我们则需要2个字节( 2 * 8 = 16 ) 来存储内存地址,所以它的大小应该是`16 * 2 = 32`,然后每2个连续的内存单元来共同存储一个内存地址;32位机则需要4个字节,64位机则需要8个字节。
## 第二次添加数据
`put(cbr1000rr, null);` ,计算cbr1000rr的hash值与15相与的值为8
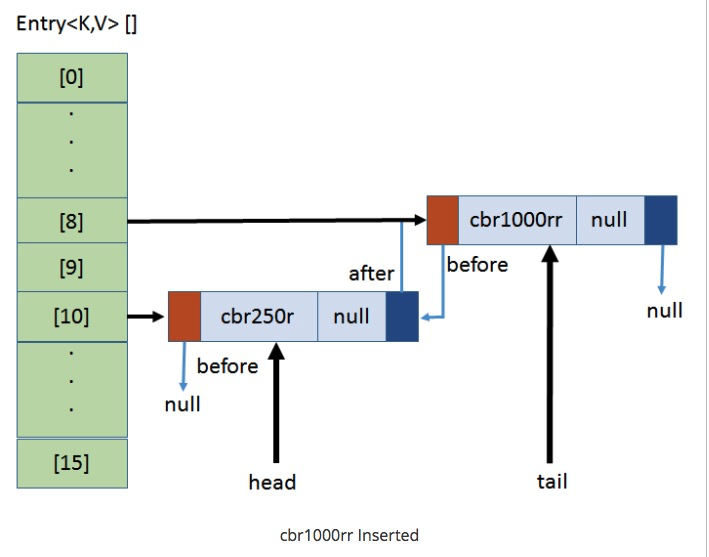
* head不变,tail指向了新的数据。同时更新原数据的after及新数据的before,达到首尾互联的目的。
## 第三次添加数据
`put(ninja250r, null);`,计算ninja250r的hash值与15相与的值为10
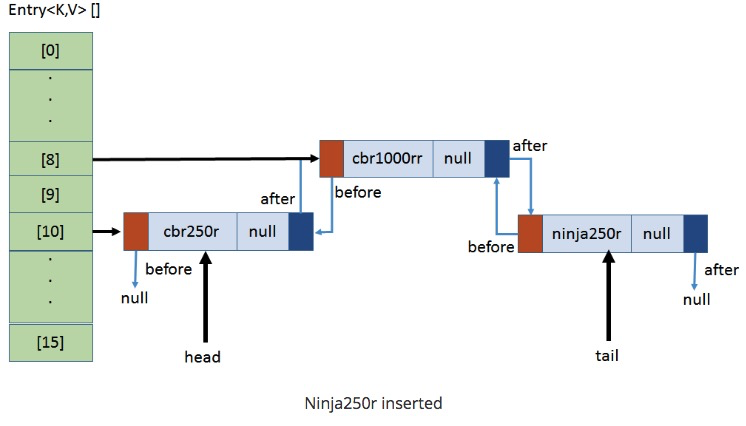
* 原10号小卡片有值,则找tail指向的数据,并将新数据的起始内存位置加入到该数据的next上。
## 第四次添加数据
`put(ninja1000rr, null);`,计算ninja1000rr的hash值与15相与的值为8
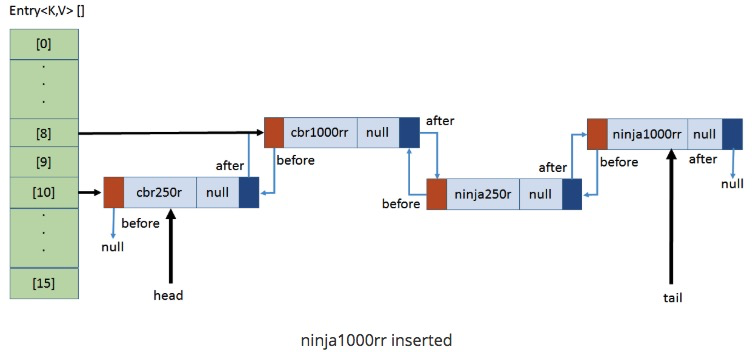
* 原8号小卡片有值,则找tail指向的数据,并将新数据的起始内存位置加入到该数据的next上。
此时,当我们需要对LinkedHashMap中的值进行便历时,便可以由head入手,一直查到tail了,而且输入的顺序与输入的顺序保持了一致。
# 其它
以上理论均基于以下现实:
* 计算机具有非凡的计算能力,特别是进行位操作,比如`与`运算
* 计算机具有直接寻址的能力,只要你告诉它内存的编号,它便可以直接定位到该内存
# 参考文档
| 名称 | 链接 | 预计学习时长(分) |
| --- | --- | --- |
| Working of LinkedHashMap | [http://www.thejavageek.com/2016/06/05/working-linkedhashmap-java/](http://www.thejavageek.com/2016/06/05/working-linkedhashmap-java/) | - |
- 序言
- 第一章:Hello World
- 第一节:Angular准备工作
- 1 Node.js
- 2 npm
- 3 WebStorm
- 第二节:Hello Angular
- 第三节:Spring Boot准备工作
- 1 JDK
- 2 MAVEN
- 3 IDEA
- 第四节:Hello Spring Boot
- 1 Spring Initializr
- 2 Hello Spring Boot!
- 3 maven国内源配置
- 4 package与import
- 第五节:Hello Spring Boot + Angular
- 1 依赖注入【前】
- 2 HttpClient获取数据【前】
- 3 数据绑定【前】
- 4 回调函数【选学】
- 第二章 教师管理
- 第一节 数据库初始化
- 第二节 CRUD之R查数据
- 1 原型初始化【前】
- 2 连接数据库【后】
- 3 使用JDBC读取数据【后】
- 4 前后台对接
- 5 ng-if【前】
- 6 日期管道【前】
- 第三节 CRUD之C增数据
- 1 新建组件并映射路由【前】
- 2 模板驱动表单【前】
- 3 httpClient post请求【前】
- 4 保存数据【后】
- 5 组件间调用【前】
- 第四节 CRUD之U改数据
- 1 路由参数【前】
- 2 请求映射【后】
- 3 前后台对接【前】
- 4 更新数据【前】
- 5 更新某个教师【后】
- 6 路由器链接【前】
- 7 观察者模式【前】
- 第五节 CRUD之D删数据
- 1 绑定到用户输入事件【前】
- 2 删除某个教师【后】
- 第六节 代码重构
- 1 文件夹化【前】
- 2 优化交互体验【前】
- 3 相对与绝对地址【前】
- 第三章 班级管理
- 第一节 JPA初始化数据表
- 第二节 班级列表
- 1 新建模块【前】
- 2 初识单元测试【前】
- 3 初始化原型【前】
- 4 面向对象【前】
- 5 测试HTTP请求【前】
- 6 测试INPUT【前】
- 7 测试BUTTON【前】
- 8 @RequestParam【后】
- 9 Repository【后】
- 10 前后台对接【前】
- 第三节 新增班级
- 1 初始化【前】
- 2 响应式表单【前】
- 3 测试POST请求【前】
- 4 JPA插入数据【后】
- 5 单元测试【后】
- 6 惰性加载【前】
- 7 对接【前】
- 第四节 编辑班级
- 1 FormGroup【前】
- 2 x、[x]、{{x}}与(x)【前】
- 3 模拟路由服务【前】
- 4 测试间谍spy【前】
- 5 使用JPA更新数据【后】
- 6 分层开发【后】
- 7 前后台对接
- 8 深入imports【前】
- 9 深入exports【前】
- 第五节 选择教师组件
- 1 初始化【前】
- 2 动态数据绑定【前】
- 3 初识泛型
- 4 @Output()【前】
- 5 @Input()【前】
- 6 再识单元测试【前】
- 7 其它问题
- 第六节 删除班级
- 1 TDD【前】
- 2 TDD【后】
- 3 前后台对接
- 第四章 学生管理
- 第一节 引入Bootstrap【前】
- 第二节 NAV导航组件【前】
- 1 初始化
- 2 Bootstrap格式化
- 3 RouterLinkActive
- 第三节 footer组件【前】
- 第四节 欢迎界面【前】
- 第五节 新增学生
- 1 初始化【前】
- 2 选择班级组件【前】
- 3 复用选择组件【前】
- 4 完善功能【前】
- 5 MVC【前】
- 6 非NULL校验【后】
- 7 唯一性校验【后】
- 8 @PrePersist【后】
- 9 CM层开发【后】
- 10 集成测试
- 第六节 学生列表
- 1 分页【后】
- 2 HashMap与LinkedHashMap
- 3 初识综合查询【后】
- 4 综合查询进阶【后】
- 5 小试综合查询【后】
- 6 初始化【前】
- 7 M层【前】
- 8 单元测试与分页【前】
- 9 单选与多选【前】
- 10 集成测试
- 第七节 编辑学生
- 1 初始化【前】
- 2 嵌套组件测试【前】
- 3 功能开发【前】
- 4 JsonPath【后】
- 5 spyOn【后】
- 6 集成测试
- 7 @Input 异步传值【前】
- 8 值传递与引入传递
- 9 @PreUpdate【后】
- 10 表单验证【前】
- 第八节 删除学生
- 1 CSS选择器【前】
- 2 confirm【前】
- 3 功能开发与测试【后】
- 4 集成测试
- 5 定制提示框【前】
- 6 引入图标库【前】
- 第九节 集成测试
- 第五章 登录与注销
- 第一节:普通登录
- 1 原型【前】
- 2 功能设计【前】
- 3 功能设计【后】
- 4 应用登录组件【前】
- 5 注销【前】
- 6 保留登录状态【前】
- 第二节:你是谁
- 1 过滤器【后】
- 2 令牌机制【后】
- 3 装饰器模式【后】
- 4 拦截器【前】
- 5 RxJS操作符【前】
- 6 用户登录与注销【后】
- 7 个人中心【前】
- 8 拦截器【后】
- 9 集成测试
- 10 单例模式
- 第六章 课程管理
- 第一节 新增课程
- 1 初始化【前】
- 2 嵌套组件测试【前】
- 3 async管道【前】
- 4 优雅的测试【前】
- 5 功能开发【前】
- 6 实体监听器【后】
- 7 @ManyToMany【后】
- 8 集成测试【前】
- 9 异步验证器【前】
- 10 详解CORS【前】
- 第二节 课程列表
- 第三节 果断
- 1 初始化【前】
- 2 分页组件【前】
- 2 分页组件【前】
- 3 综合查询【前】
- 4 综合查询【后】
- 4 综合查询【后】
- 第节 班级列表
- 第节 教师列表
- 第节 编辑课程
- TODO返回机制【前】
- 4 弹出框组件【前】
- 5 多路由出口【前】
- 第节 删除课程
- 第七章 权限管理
- 第一节 AOP
- 总结
- 开发规范
- 备用