如果参与过小型团队的生产项目开发,相信你一定被不统一的数据表弄的晕头转向过。代码`pull`到本地后,各种`error`便迫不急待的跳出来与我们会面了。产生问题的原因也很简单:代码与地数据环境不一致。
本节中,让我们使用另外一种集成度高且使用较简单的方法 --- `Spring Data JPA`来使用`JAVA`代码进行数据表的维护。
# ER图
在建立数据表以前,我们首先需要建立数据表图----ER(Entity-relationship model)图。ER图又称为实体关系图,描述的是数据表(实体)信息及数据表(实体)之间的关联信息。当前系统存在两个数据表:教师表、班级表。两个表的关系为:每个班级必然对应1个教师,每个教师可能对应0个或多个班级,所以`教师`与`班级`的关系是`1 : 0..1`。
用ER图来表示为:
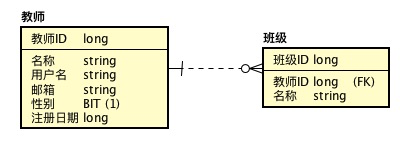
除了这种表现形式(IE)以外,还可以用以下形式(IDEF1X)来表示:
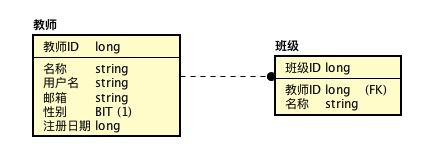
它们只是表现的形式不同而已,所表达的含意是一样的。
在团队的项目中,我们在创建ER图时为了更好的和类图相对应,我们规定:
| ER图(JAVA)类型 | 数据表类型 | 备注 |
| ---- | ---- | ---- |
| Long | bigint | Long在java中为64位,bigint在mysql同为64位 |
| String | varchar(255) | 假设字符串的默认长度为255 |
# 自动建表
参考ER图,下面来展示如何使用`Spring Data JPA`来进行数据表的维护。
## 引用依赖
由于`Spring Data JPA`并不属于`Spring Boot`的核心模块,所以在使用JPA时,需要在`pom.xml`中添加如下依赖。
pom.xml
```
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency> ✚ ➊
<groupId>org.springframework.boot</groupId> ✚ ➋
<artifactId>spring-boot-starter-data-jpa</artifactId> ✚ ➌
</dependency> ✚
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
```
* ➊ 添加新的依赖.
* ➋ 依赖的包所在的班级。
* ➌ 依赖的包的名字。
`pom.xml`变更后IDEA会自动在右下角提示是否自动导入该包,选择`是`即可,这样以后如果该文件再有变更,IDEA则会自动的为我们处理这些变更。如果IDEA没有为我们自动处理或者我们想手动的处理这些依赖,那么也可以打开控制台执行:`mvn install`来手动完成依赖更新。
> IDEA处理依赖的时间长短取决于我们的网络状况,可以点击软件右下角的当前任务来查看处理进度。
## 配置信息
我们找到`src/main/resources/application.properties`,并增加:`spring.jpa.hibernate.ddl-auto`配置项:
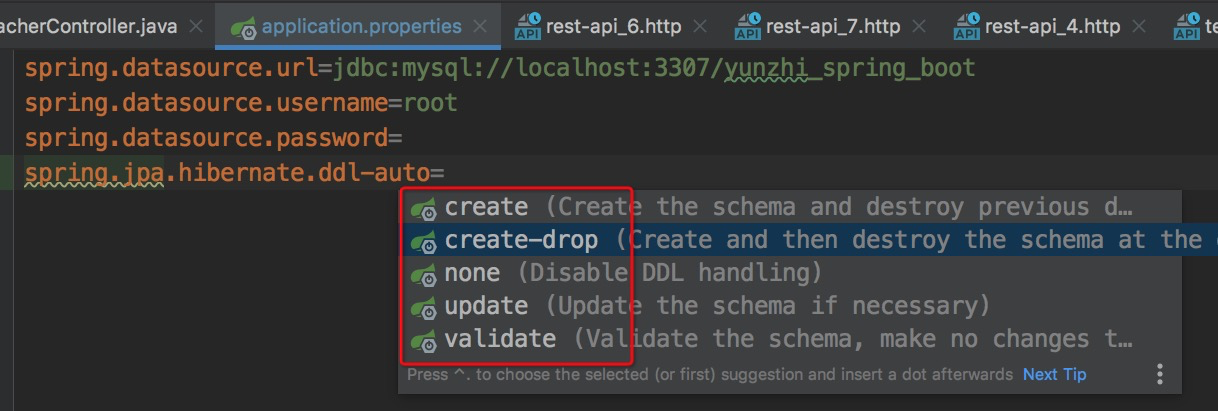
配置项有5个:`create`创建数据表、`create-drop`先创建数据表程序终止时删除数据表、`none`什么也不做、`update`更新数据表、`validate`较验证表。
在此,我们暂时使用`create-drop`做为配置项。
我们虽然在前面配置过数据的连接信息`spring.datasource.url`为`jdbc:mysql:`,即已经指名了数据库使用的为`mysql` 。但`mysql`的版本众多,不同的版本间存在一定的差异,为了让`JPA`能够更好的自动处理这些差异,我们还需要配置数据库`方言`信息。
src/main/resources/application.properties
```
spring.datasource.url=jdbc:mysql://localhost:3307/yunzhi_spring_boot
spring.datasource.username=root
spring.datasource.password=
spring.jpa.hibernate.ddl-auto=create-drop
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect ➊
```
* ➊ 告知JPA,我们使用的是`mysql5.7`版本。
如果你使用的是`mysql5.5`或`mysql5.6`,请将上述配置修正为`MySQL55Dialect`。如果你使用的是`MariaDB`请按下图对应修改:
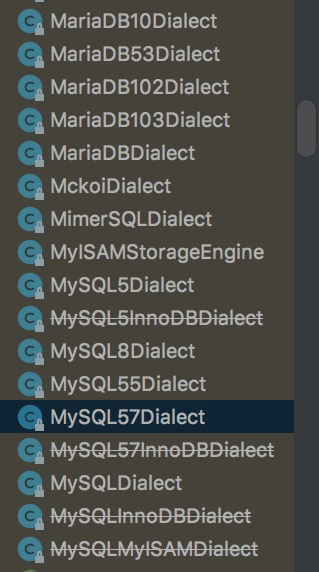
**注意:** 类拟于~~MySQL57InnoDBDialect~~这样的标识表示该类的存在为兼容历史版本,其已经被当前版本弃用而不建议使用了。
## 建立对应的类
我们先建立个`package`,命名为`entity`。
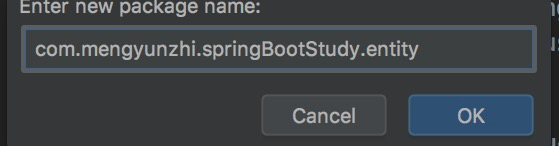
然后在该包下新建Klass类。
```
.
├── SpringBootStudyApplication.java
├── Teacher.java
├── TeacherController.java
└── entity
└── Klass.java
```
代码如下:
entity/Klass.java
```
package com.mengyunzhi.springBootStudy.entity;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity ➊
public class Klass {
@Id ➎
@GeneratedValue(strategy = GenerationType.IDENTITY) ➏ ➐
private Long id; ➋
private Long teacherId; ➋
private String name; ➋
public Klass() { ➌
}
public Long getId() { ➍
return id;
}
public void setId(Long id) { ➍
this.id = id;
}
public Long getTeacherId() {
return teacherId;
}
public void setTeacherId(Long teacherId) {
this.teacherId = teacherId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
```
* ➊ 说明Klass是一个与数据表相关的类,在系统启动时将参考该类来`create 生成`、`update 更新`或`validate 验证`数据表
* ➋ 定义相关字段
* ➌ 国际惯例,构建空的构建函数。
* ➍ 国际惯例,设置set/get函数。
* ➎ 说明此数据表的主键为id。
* ➏➐ 定义主健的自增属性。
## 测试
我们重新启动项目,并使用navicate查看数据库:
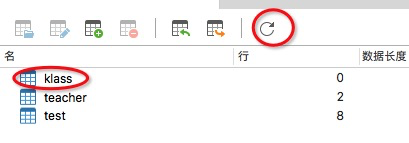
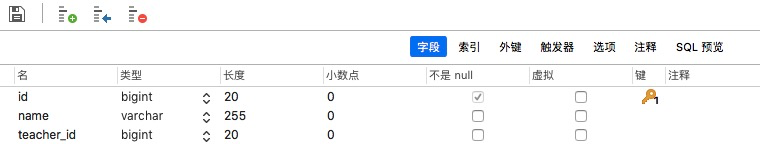
通过观察可得JPA自动实现了以下功能:
* 将JAVA类`Klass`转换为`klass`表。
* 将JAVA类中的属性名转换成了字段名。
* 将`@Id`注解的属性转换为主键且`not null`
* 将`@GeneratedValue(strategy = GenerationType.IDENTITY) `注解转换为自增。
* 在转换的过程中,将驼峰式命名转换为下划线式命名。
未实现的功能:
* 未设置数据表外键`teacher_id`。
此时,我们如果点击项目停止按钮:

来停止项目,由于我们在前面设置了`create-drop`属性,所以刚刚为我们自动创建的数据表`klass`会被自动删除掉。这样便达到了:在团队开发中,只要保证`pull`的代码是最新的,那么数据表必然也会是同步更新的。
# 设置外键
`JPA`只所以没有成功的设置外键,是由于对`JPA`而言只有使用`@Entity`注解的类才被认为是数据表,所以其认为当前仅有一个`klass`表,在没有`teacher`表的前提下,`JPA`也就当然的无法为我们自动添加此外键了。为了让`JPA`能够看到`teacher`表,我们可以参考`Klass`类建立一个`Teacher`类。写到这我们发现在前面的章节中,我们已经建立了如下的`Teacher`类了:
Teacher.java
```java
package com.mengyunzhi.springBootStudy;
/**
* 教师模型,用于更方便的存储查表后返回的数据
*/
public class Teacher {
private Long id;
private String name;
private Boolean sex;
private String username;
private String email;
private Long createTime;
private Long updateTime;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Boolean getSex() {
return sex;
}
public void setSex(Boolean sex) {
this.sex = sex;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Long getCreateTime() {
return createTime;
}
public void setCreateTime(Long createTime) {
this.createTime = createTime;
}
public Long getUpdateTime() {
return updateTime;
}
public void setUpdateTime(Long updateTime) {
this.updateTime = updateTime;
}
}
```
与`Klass`相比较,我们只需要增加以下信息该类便自动对应起了数据表:
* ★ 说明该类对应数据表。
* ☆ 构建空的构造函数。
* ★ 设置主键。
* ★ 定义主健的自增属性。
> ☆非必要条件;★必要条件。
参考上述四点对`Teacher`表进行改造如下:
```
package com.mengyunzhi.springBootStudy;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
/**
* 教师模型,用于更方便的存储查表后返回的数据
*/
@Entity ①
public class Teacher {
@Id ③
@GeneratedValue(strategy = GenerationType.IDENTITY) ④
private Long id;
private String name;
private Boolean sex;
private String username;
private String email;
private Long createTime;
private Long updateTime;
public Teacher() { ②
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Boolean getSex() {
return sex;
}
public void setSex(Boolean sex) {
this.sex = sex;
}
public String getUsername() {
return username;
}
public void setUsername(String username) {
this.username = username;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Long getCreateTime() {
return createTime;
}
public void setCreateTime(Long createTime) {
this.createTime = createTime;
}
public Long getUpdateTime() {
return updateTime;
}
public void setUpdateTime(Long updateTime) {
this.updateTime = updateTime;
}
}
```
## 测试
我们删除数据库中所有的数据表,然后重新运行后台项目,验证是否为我们生成了相应的数据表并对应生成了相应的字段。
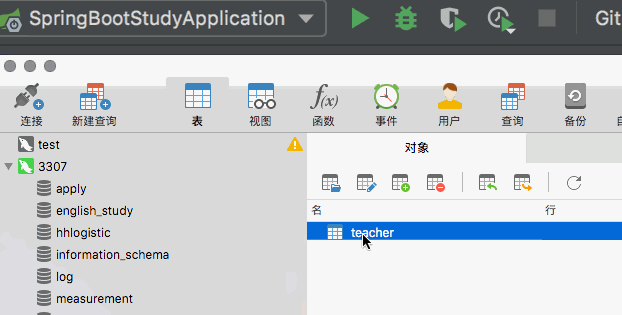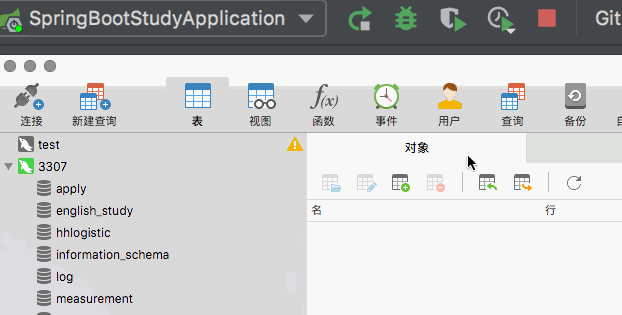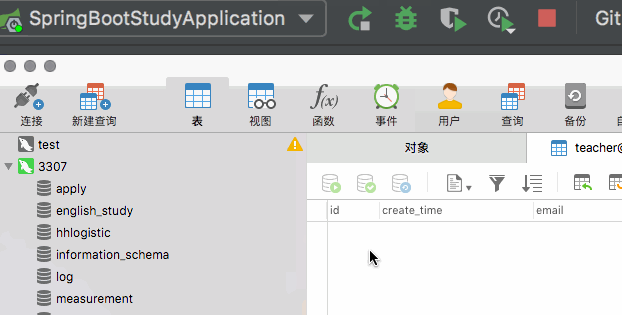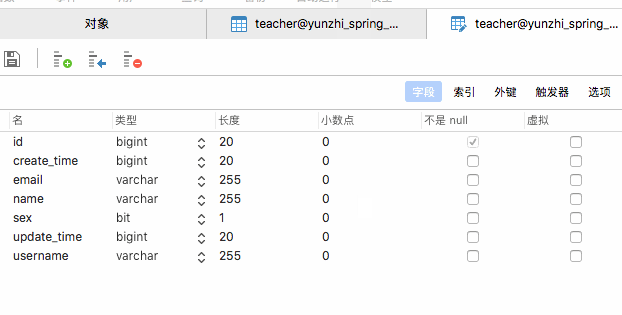
和我们的预期相一致,JPA非常出色的完成了此项任务。前且当遇到`Boolean`类型时,`JPA`自动的将其转换为`bit(1)`。
## 添加外键
实体(数据表)与实体间的关系分为以下四种:1对1,1对多,多对1,多对多;在英文中分别是OneToOne、OneToMany、ManyToOne、ManyToMany;在ER图中,我们还会用1:1、1:N、N:1、 M:N 来表示。在`JPA`声明外键只需要:
entity/Klass.java
```
private Long teacherId; ✘
@ManyToOne ✚ ➋
private Teacher teacher; ✚ ➊
// 省略了getter/setter函数
```
* ➊ 类型定义为Teacher实体类
* ➋ 该字段与Teacher实体关联,关系为多对1。
## 测试
测试是否生成了相应的字段:
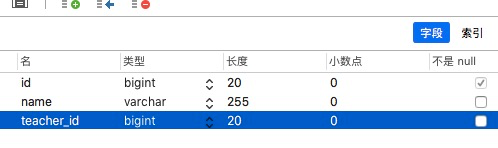
不止如此,`JPA`还自动为我们添加了索引:

同时自动为我们添加了外键:

这已经完成的符合并超出了我们的预期。
# Spring Data JPA
再认识了`Spring Data JPA`以后,我们再深入地了解下`JPA ---- Java Persistence API JAVA持久层应用接口`。
什么是`持久层`呢,它的作用是什么呢?简单来讲`持久层`的作用就是通过`持久化`的操作将数据保存到数据库当中。`持久化`其实就是`保存数据`的另一种描述方法,只所以这么讲我猜是由于:在数据成功的保存到数据库中以前,数据是在内存中保存的,我们知道内存中的数据是可能随时删除、变更以及被抛弃丢失的(比如突然的停电了),而保存到数据库中以后即使发生了停电的现象,该数据也会不丢失。就像现实生活中我们会把一些我们认为重要的东西记在笔记本上,免得哪天想用这个知识的时候忘记了,这个记笔记的过程在计算机中就做`持久化`。
由于`JPA`本质上是个`接口`,而`接口`的本质就是`规范`。所以通俗来说,`JPA`就是一个在`JAVA`程序下进行数据访问的一种`规范`。而实现这个规范的技术有很多,比如我们刚刚使用的`Spring Data JPA`,除此以外,比较出名的`JPA`还有`hibernate`及`mybatis`。实际上`Spring Data JPA`也是基于`hibernate`的。
为了更好的理解接口与实现我们再拿USB做个例子:其实USB2.0 ,USE3.0都是规范,确切的来说他们就是几张纸一堆文字,规定了接口的大小、形状、有几个触点、每个触点传输什么数据以及如何传输数据等等等等。而我们使用的USE鼠标、U盘等都是在这个规范下的实现。他们的设计遵从了USE规范,从而使其能够与其它同样遵守该规范的设备协作运行。
那么什么是`Spring Data JPA`呢?官方如是说:
*****
Spring Data JPA, part of the larger Spring Data family, makes it easy to easily implement JPA based repositories. This module deals with enhanced support for JPA based data access layers. It makes it easier to build Spring-powered applications that use data access technologies.
Implementing a data access layer of an application has been cumbersome for quite a while. Too much boilerplate code has to be written to execute simple queries as well as perform pagination, and auditing. Spring Data JPA aims to significantly improve the implementation of data access layers by reducing the effort to the amount that’s actually needed. As a developer you write your repository interfaces, including custom finder methods, and Spring will provide the implementation automatically.
*****
大概的意思就是说,`Spring Data JPA`也是`JPA`,它更简单、更强大。
# 参考文档
| 名称 | 链接 | 预计学习时长(分) |
| --- | --- | --- |
| 什么是JPA | [https://baike.baidu.com/item/JPA](https://baike.baidu.com/item/JPA) | 10 |
| What's JPA | [https://en.wikipedia.org/wiki/Java\_Persistence\_API](https://en.wikipedia.org/wiki/Java_Persistence_API) | 20 |
| Spring Data JPA | [https://spring.io/projects/spring-data-jpa](https://spring.io/projects/spring-data-jpa) | 5 |
| Accessing Data with JPA | [https://spring.io/guides/gs/accessing-data-jpa/](https://spring.io/guides/gs/accessing-data-jpa/) | 15 |
| 源码地址 | [https://github.com/mengyunzhi/spring-boot-and-angular-guild/releases/tag/step3.1](https://github.com/mengyunzhi/spring-boot-and-angular-guild/releases/tag/step3.1) | - |
- 序言
- 第一章:Hello World
- 第一节:Angular准备工作
- 1 Node.js
- 2 npm
- 3 WebStorm
- 第二节:Hello Angular
- 第三节:Spring Boot准备工作
- 1 JDK
- 2 MAVEN
- 3 IDEA
- 第四节:Hello Spring Boot
- 1 Spring Initializr
- 2 Hello Spring Boot!
- 3 maven国内源配置
- 4 package与import
- 第五节:Hello Spring Boot + Angular
- 1 依赖注入【前】
- 2 HttpClient获取数据【前】
- 3 数据绑定【前】
- 4 回调函数【选学】
- 第二章 教师管理
- 第一节 数据库初始化
- 第二节 CRUD之R查数据
- 1 原型初始化【前】
- 2 连接数据库【后】
- 3 使用JDBC读取数据【后】
- 4 前后台对接
- 5 ng-if【前】
- 6 日期管道【前】
- 第三节 CRUD之C增数据
- 1 新建组件并映射路由【前】
- 2 模板驱动表单【前】
- 3 httpClient post请求【前】
- 4 保存数据【后】
- 5 组件间调用【前】
- 第四节 CRUD之U改数据
- 1 路由参数【前】
- 2 请求映射【后】
- 3 前后台对接【前】
- 4 更新数据【前】
- 5 更新某个教师【后】
- 6 路由器链接【前】
- 7 观察者模式【前】
- 第五节 CRUD之D删数据
- 1 绑定到用户输入事件【前】
- 2 删除某个教师【后】
- 第六节 代码重构
- 1 文件夹化【前】
- 2 优化交互体验【前】
- 3 相对与绝对地址【前】
- 第三章 班级管理
- 第一节 JPA初始化数据表
- 第二节 班级列表
- 1 新建模块【前】
- 2 初识单元测试【前】
- 3 初始化原型【前】
- 4 面向对象【前】
- 5 测试HTTP请求【前】
- 6 测试INPUT【前】
- 7 测试BUTTON【前】
- 8 @RequestParam【后】
- 9 Repository【后】
- 10 前后台对接【前】
- 第三节 新增班级
- 1 初始化【前】
- 2 响应式表单【前】
- 3 测试POST请求【前】
- 4 JPA插入数据【后】
- 5 单元测试【后】
- 6 惰性加载【前】
- 7 对接【前】
- 第四节 编辑班级
- 1 FormGroup【前】
- 2 x、[x]、{{x}}与(x)【前】
- 3 模拟路由服务【前】
- 4 测试间谍spy【前】
- 5 使用JPA更新数据【后】
- 6 分层开发【后】
- 7 前后台对接
- 8 深入imports【前】
- 9 深入exports【前】
- 第五节 选择教师组件
- 1 初始化【前】
- 2 动态数据绑定【前】
- 3 初识泛型
- 4 @Output()【前】
- 5 @Input()【前】
- 6 再识单元测试【前】
- 7 其它问题
- 第六节 删除班级
- 1 TDD【前】
- 2 TDD【后】
- 3 前后台对接
- 第四章 学生管理
- 第一节 引入Bootstrap【前】
- 第二节 NAV导航组件【前】
- 1 初始化
- 2 Bootstrap格式化
- 3 RouterLinkActive
- 第三节 footer组件【前】
- 第四节 欢迎界面【前】
- 第五节 新增学生
- 1 初始化【前】
- 2 选择班级组件【前】
- 3 复用选择组件【前】
- 4 完善功能【前】
- 5 MVC【前】
- 6 非NULL校验【后】
- 7 唯一性校验【后】
- 8 @PrePersist【后】
- 9 CM层开发【后】
- 10 集成测试
- 第六节 学生列表
- 1 分页【后】
- 2 HashMap与LinkedHashMap
- 3 初识综合查询【后】
- 4 综合查询进阶【后】
- 5 小试综合查询【后】
- 6 初始化【前】
- 7 M层【前】
- 8 单元测试与分页【前】
- 9 单选与多选【前】
- 10 集成测试
- 第七节 编辑学生
- 1 初始化【前】
- 2 嵌套组件测试【前】
- 3 功能开发【前】
- 4 JsonPath【后】
- 5 spyOn【后】
- 6 集成测试
- 7 @Input 异步传值【前】
- 8 值传递与引入传递
- 9 @PreUpdate【后】
- 10 表单验证【前】
- 第八节 删除学生
- 1 CSS选择器【前】
- 2 confirm【前】
- 3 功能开发与测试【后】
- 4 集成测试
- 5 定制提示框【前】
- 6 引入图标库【前】
- 第九节 集成测试
- 第五章 登录与注销
- 第一节:普通登录
- 1 原型【前】
- 2 功能设计【前】
- 3 功能设计【后】
- 4 应用登录组件【前】
- 5 注销【前】
- 6 保留登录状态【前】
- 第二节:你是谁
- 1 过滤器【后】
- 2 令牌机制【后】
- 3 装饰器模式【后】
- 4 拦截器【前】
- 5 RxJS操作符【前】
- 6 用户登录与注销【后】
- 7 个人中心【前】
- 8 拦截器【后】
- 9 集成测试
- 10 单例模式
- 第六章 课程管理
- 第一节 新增课程
- 1 初始化【前】
- 2 嵌套组件测试【前】
- 3 async管道【前】
- 4 优雅的测试【前】
- 5 功能开发【前】
- 6 实体监听器【后】
- 7 @ManyToMany【后】
- 8 集成测试【前】
- 9 异步验证器【前】
- 10 详解CORS【前】
- 第二节 课程列表
- 第三节 果断
- 1 初始化【前】
- 2 分页组件【前】
- 2 分页组件【前】
- 3 综合查询【前】
- 4 综合查询【后】
- 4 综合查询【后】
- 第节 班级列表
- 第节 教师列表
- 第节 编辑课程
- TODO返回机制【前】
- 4 弹出框组件【前】
- 5 多路由出口【前】
- 第节 删除课程
- 第七章 权限管理
- 第一节 AOP
- 总结
- 开发规范
- 备用