
# 7L Selenium IDE – 定位元素(续)
> 原文: [https://javabeginnerstutorial.com/selenium/7l-ide-locating-elements-contd/](https://javabeginnerstutorial.com/selenium/7l-ide-locating-elements-contd/)
嗨呀测试人员! 我回来了,比赛开始了! 让我们继续前进,在我们的网页上找到一些古怪的元素!!
在这篇文章中,我们将看到:
定位依据
* CSS
* DOM
* XPath
让我们一一看一下。
## 通过 CSS 定位
CSS(层叠样式表)将样式添加到网页中,通常用于描述 HTML 文档的显示或呈现。 为了将这些样式属性绑定到文档中的元素,使用了 **CSS 选择器**。 这些选择器用于根据其名称,ID,类,属性等的组合来选择 HTML 元素。
通常,高级 Selenium 用户会通过这种方法在网页上定位元素。 它有点复杂,但主要在元素没有 ID 或名称的情况下首选。
指定目标的格式以标签“`css =`”开头,后跟相应的标签名称和其他必需元素。 让我们欣赏使用最常用的 CSS 选择器定位元素的巨大优势。
### 标签和 ID
HTML 标记和元素的 ID 与井号(`#`)一起使用。
*格式*: `css = tag#id`
*示例*:打开 Amazon 的登录页面。 让我们找到“电子邮件(用于移动帐户的电话)”文本框。
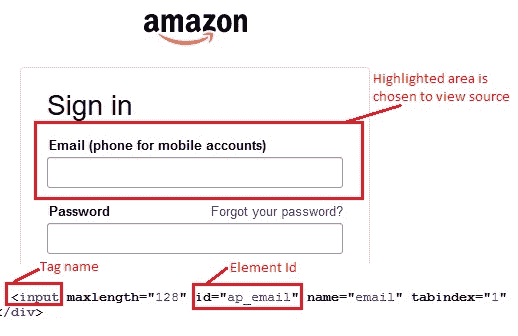
标记名称为“输入”,元素的 ID 为“`ap_email`”。
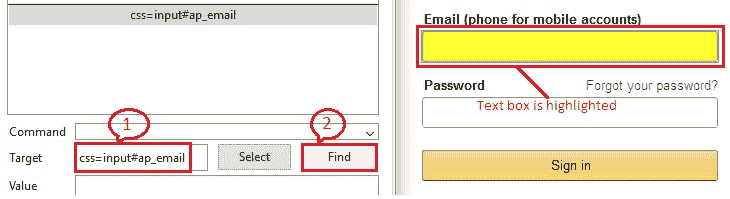
因此,按照目标格式,输入“`css = input#ap_email`”并单击“查找”按钮将按预期突出显示网页上的“电子邮件”文本框。
### 标签和类别
此方法使用 HTML 标记和要访问的元素的类以及点(`.`)符号。
*格式*:`css = tag.class`
*示例*:打开 Indeed.com,让我们突出显示文本“`what`”。

标签名称为“`td`”,元素的类别为“`npb`”。

输入“`css = td.npb`”,然后单击“查找”按钮,将突出显示文本“`what`”。 如果多个元素具有相同的标记和类名称,则仅会识别与条件匹配的第一个元素。 在这种情况下必须使用过滤器。 在之前的博客文章中对此概念进行了详细说明。
### 标签和属性
在此方法中使用 HTML 标记,最好使用要访问的元素的唯一属性及其对应的值。 属性和值用方括号[]括起来。
*格式*: `css = tag[prop=value]`
*示例*:打开亚马逊登录页面,让我们找到“电子邮件”文本框。
标签名称为“`input`”,属性为“`name`”,其对应值为“`email`”。
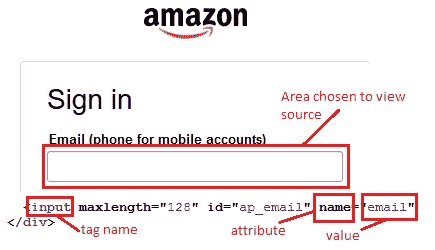
为目标输入“`css = input[name=email]`”,然后单击“查找”按钮,将突出显示“电子邮件”文本框。

### 标签,类和属性
这与“标记和属性”定位策略相似,但是带有类名和点(`.`)符号。 通常在两个 Web 元素具有相同的标记和类名称时使用。
*格式*: `css = tag.class[prop=value]`
*示例*:打开 facebook.com,让我们找到“电子邮件或电话”文本框。
请注意下图,“电子邮件”和“密码”文本框具有相同的标签“`input`”和相同的类名“`inputtext`”,但属性“`tabindex`”的值不同。

因此,标签名称为“`input`”,类为“`inputtext`”,属性为“`tabindex`”且其对应值为“1”的标签将突出显示“电子邮件或电话”文本框。 属性值与“2”相同的组合将突出显示“密码”文本框。
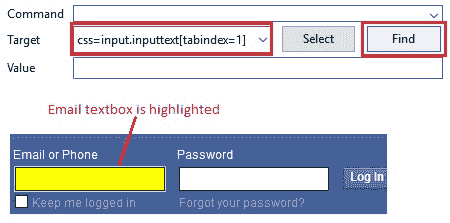
输入“`css = input.inputtext[tabindex=1]`”以突出显示“电子邮件或电话”文本框。
### 内部文本
在某些情况下,ID,类或属性未用于特定元素。 要找到这样的元素,可以使用网页上显示的实际文本(内部文本)。
*格式*: `css = tag:contains("innerText")`
*示例*:打开亚马逊登录页面,让我们突出显示文本“`Password`”。
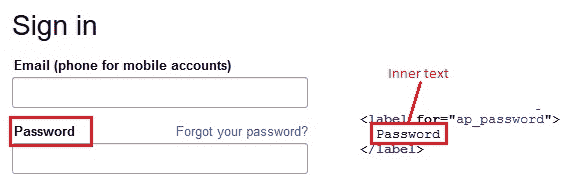
这里的标签是“`label`”,内部文本是“`Password`”。 输入“`css = lable:contains("Password")`”高亮显示文本“`Password`”。

## 通过 DOM 定位
文档对象模型是用于表示 HTML 文档中元素的约定。 定位策略利用了 DOM 模型中使用的树结构。 因此,使用分层的点分符号来获取元素的位置。
指定 DOM 定位器时,不需要“`dom =`”标签,因为只有 DOM 定位器以单词“`document`”开头。
*示例*代码:

*方法 1*:`document.getElementById("testForm")`– 使用元素的 ID。
*方法 2*:`document.forms[0]` – “表单”将返回文档中使用的所有表单的集合。 因此,使用索引以唯一的方式指定被测元素。
*方法 3*:`document.forms[0].user1` – 第一种形式,访问`user1`元素。
*方法 4*:`document.getElementsByName("seatingClass")[1]` – “`getElementsByName`”也将返回括号内指定名称相同的元素集合。 因此,索引返回所需的元素。 在这种情况下,可以访问业务单选按钮。 如果使用索引`[0]`,则可以访问经济单选按钮。
*方法 5*:访问`document.forms["testForm"].elements["user2"]` – 名为“`testForm`”的表单的`user2`。
*方法 6*:`document.forms[1].elements[2]` – 这将返回“`seatingClassForm`”中的“第一个”单选按钮。
现在是时候使用 Selenium IDE 探索 Web 应用的 DOM 了。
## 通过 XPath 定位
XPath 是一种语法,用于在 XML 文档中导航和定位节点。 由于 HTML 只是 XML 的实现,因此可以使用 XPath 策略来查找所需的元素。
如果找不到合适的 ID,名称或类等来查找元素,则可以使用 XPath。 使用 XPath 定位元素有两种。 一个是绝对路径(不建议使用),因为它会在对现有 HTML 代码进行最小改动的情况下中断。 另一个选项是相对路径 – 使用 ID 或名称查找附近的元素,并使用两者之间的关系使用 XPath 查找所需的元素。 因此,几乎可以使用 XPath 策略定位网页上的任何元素。
这种定位策略非常复杂,通常是高级 Selenium 用户首选的定位策略。 但是不用担心! 为了使整个 XPath 查找方法变得容易,我们将“Firebug”作为 Firefox 浏览器的附加组件。 很快您就会遇到一篇博客文章,该文章完全致力于 Firebug 的安装和使用! 欢呼!!
另外,由于仅 XPath 定位符以“`//`”开头,因此不需要为 XPath 定位符指定“`xpath =`”。
*示例*:打开 Amazon 登录页面,然后让我们使用 XPath 找到“电子邮件”文本框。
点击 Firebug 图标并检查所需的元素(在本例中为“电子邮件”文本框)。 相应的源代码将显示在网页的下部。

右键点击突出显示的代码,然后选择“复制 XPath”,如下所示。

在目标中,输入一个正斜杠(`/`),然后使用 Firebug 粘贴复制的 XPath,“`//html/body/div[1]/div[1]/div[3]/div/div[2]/form/div/div/div/div[1]/input`”。 请注意,XPath 定位符应以两个正斜杠开头。

因此,“电子邮件”文本框将按预期突出显示。
你去! 我们刚刚完成了各种可用的定位策略。 是的,要选择的定位器类型完全取决于要测试的应用。
在将如此多的知识融入您的大脑之后,我知道您将每年两次要求我六个月的假期。 因此,在另一篇文章中再见。
祝你今天愉快!
- JavaBeginnersTutorial 中文系列教程
- Java 教程
- Java 教程 – 入门
- Java 的历史
- Java 基础知识:Java 入门
- jdk vs jre vs jvm
- public static void main(string args[])说明
- 面向初学者的 Java 类和对象教程
- Java 构造器
- 使用 Eclipse 编写 Hello World 程序
- 执行顺序
- Java 中的访问修饰符
- Java 中的非访问修饰符
- Java 中的数据类型
- Java 中的算术运算符
- Java 语句初学者教程
- 用 Java 创建对象的不同方法
- 内部类
- 字符串构建器
- Java 字符串教程
- Java 教程 – 变量
- Java 中的变量
- Java 中的局部变量
- Java 中的实例变量
- Java 引用变量
- 变量遮盖
- Java 教程 – 循环
- Java for循环
- Java 教程 – 异常
- Java 异常教程
- 异常处理 – try-with-resources语句
- Java 异常处理 – try catch块
- Java 教程 – OOPS 概念
- Java 重载
- Java 方法覆盖
- Java 接口
- 继承
- Java 教程 – 关键字
- Java 中的this关键字
- Java static关键字
- Java 教程 – 集合
- Java 数组教程
- Java 集合
- Java 集合迭代器
- Java Hashmap教程
- 链表
- Java 初学者List集合教程
- Java 初学者的Map集合教程
- Java 初学者的Set教程
- Java 初学者的SortedSet集合教程
- Java 初学者SortedMap集合教程
- Java 教程 – 序列化
- Java 序列化概念和示例
- Java 序列化概念和示例第二部分
- Java 瞬态与静态变量
- serialVersionUID的用途是什么
- Java 教程 – 枚举
- Java 枚举(enum)
- Java 枚举示例
- 核心 Java 教程 – 线程
- Java 线程教程
- Java 8 功能
- Java Lambda:初学者指南
- Lambda 表达式简介
- Java 8 Lambda 列表foreach
- Java 8 Lambda 映射foreach
- Java 9
- Java 9 功能
- Java 10
- Java 10 独特功能
- 核心 Java 教程 – 高级主题
- Java 虚拟机基础
- Java 类加载器
- Java 开发人员必须知道..
- Selenium 教程
- 1 什么是 Selenium?
- 2 为什么要进行自动化测试?
- 3 Selenium 的历史
- 4 Selenium 工具套件
- 5 Selenium 工具支持的浏览器和平台
- 6 Selenium 工具:争霸
- 7A Selenium IDE – 简介,优点和局限性
- 7B Selenium IDE – Selenium IDE 和 Firebug 安装
- 7C Selenium IDE – 突破表面:初探
- 7D Selenium IDE – 了解您的 IDE 功能
- 7E Selenium IDE – 了解您的 IDE 功能(续)。
- 7F Selenium IDE – 命令,目标和值
- 7G Selenium IDE – 记录和运行测试用例
- 7H Selenium IDE – Selenium 命令一览
- 7I Selenium IDE – 设置超时,断点,起点
- 7J Selenium IDE – 调试
- 7K Selenium IDE – 定位元素(按 ID,名称,链接文本)
- 7L Selenium IDE – 定位元素(续)
- 7M Selenium IDE – 断言和验证
- 7N Selenium IDE – 利用 Firebug 的优势
- 7O Selenium IDE – 以所需的语言导出测试用例
- 7P Selenium IDE – 其他功能
- 7Q Selenium IDE – 快速浏览插件
- 7Q Selenium IDE – 暂停和反射
- 8 给新手的惊喜
- 9A WebDriver – 架构及其工作方式
- 9B WebDriver – 在 Eclipse 中设置
- 9C WebDriver – 启动 Firefox 的第一个测试脚本
- 9D WebDriver – 执行测试
- 9E WebDriver – 用于启动其他浏览器的代码示例
- 9F WebDriver – JUnit 环境设置
- 9G WebDriver – 在 JUnit4 中运行 WebDriver 测试
- 9H WebDriver – 隐式等待
- 9I WebDriver – 显式等待
- 9J WebDriver – 定位元素:第 1 部分(按 ID,名称,标签名称)
- 9K WebDriver – 定位元素:第 2 部分(按className,linkText,partialLinkText)
- 9L WebDriver – 定位元素:第 3a 部分(按cssSelector定位)
- 9M WebDriver – 定位元素:第 3b 部分(cssSelector续)
- 9N WebDriver – 定位元素:第 4a 部分(通过 xpath)
- 9O WebDriver – 定位元素:第 4b 部分(XPath 续)
- 9P WebDriver – 节省时间的捷径:定位器验证
- 9Q WebDriver – 处理验证码
- 9R WebDriver – 断言和验证
- 9S WebDriver – 处理文本框和图像
- 9T WebDriver – 处理单选按钮和复选框
- 9U WebDriver – 通过两种方式选择项目(下拉菜单和多项选择)
- 9V WebDriver – 以两种方式处理表
- 9W WebDriver – 遍历表元素
- 9X WebDriver – 处理警报/弹出框
- 9Y WebDriver – 处理多个窗口
- 9Z WebDriver – 最大化窗口
- 9AA WebDriver – 执行 JavaScript 代码
- 9AB WebDriver – 使用动作类
- 9AC WebDriver – 无法轻松定位元素? 继续阅读...
- 10A 高级 WebDriver – 使用 Apache ANT
- 10B 高级 WebDriver – 生成 JUnit 报告
- 10C 高级 WebDriver – JUnit 报表自定义
- 10D 高级 WebDriver – JUnit 报告自定义续
- 10E 高级 WebDriver – 生成 PDF 报告
- 10F 高级 WebDriver – 截屏
- 10G 高级 WebDriver – 将屏幕截图保存到 Word 文档
- 10H 高级 WebDriver – 发送带有附件的电子邮件
- 10I 高级 WebDriver – 使用属性文件
- 10J 高级 WebDriver – 使用 POI 从 excel 读取数据
- 10K 高级 WebDriver – 使用 Log4j 第 1 部分
- 10L 高级 WebDriver – 使用 Log4j 第 2 部分
- 10M 高级 WebDriver – 以无头模式运行测试
- Vue 教程
- 1 使用 Vue.js 的 Hello World
- 2 模板语法和反应式的初探
- 3 Vue 指令简介
- 4 Vue Devtools 设置
- 5 数据绑定第 1 部分(文本,原始 HTML,JavaScript 表达式)
- 6 数据绑定第 2 部分(属性)
- 7 条件渲染第 1 部分(v-if,v-else,v-else-if)
- 8 条件渲染第 2 部分(v-if和v-show)
- 9 渲染列表第 1 部分(遍历数组)
- 10 渲染列表第 2 部分(遍历对象)
- 11 监听 DOM 事件和事件修饰符
- 12 监听键盘和鼠标事件
- 13 让我们使用简写
- 14 使用v-model进行双向数据绑定
- 15 表单输入绑定
- 18 类绑定
- Python 教程
- Python 3 简介
- Python 基础知识 - 又称 Hello World 以及如何实现
- 如何在 Windows 中安装 python
- 适用于 Windows,Mac,Linux 的 Python 设置
- Python 数字和字符串
- Python 列表
- Python 集
- Python 字典
- Python 条件语句
- Python 循环
- Python 函数
- 面向对象编程(OOP)
- Python 中的面向对象编程
- Python 3 中的异常处理
- Python 3:猜数字
- Python 3:猜数字 – 回顾
- Python 生成器
- Hibernate 教程
- Hibernate 框架基础
- Hibernate 4 入门教程
- Hibernate 4 注解配置
- Hibernate 4 的实体关系
- Hibernate 4 中的实体继承模型
- Hibernate 4 查询语言
- Hibernate 4 数据库配置
- Hibernate 4 批处理
- Hibernate 4 缓存
- Hibernate 4 审计
- Hibernate 4 的并发控制
- Hibernate 4 的多租户
- Hibernate 4 连接池
- Hibernate 自举