# 哈夫曼编码和游程编码
# 游程编码和哈夫曼编码
## Huffman encode(哈夫曼编码)
Huffman 编码的基本思想就是用短的编码表示出现频率高的字符,用长的编码来表示出现频率低的字符,这使得编码之后的字符串的平均长度、长度的期望值降低,从而实现压缩的目的。 因此 Huffman 编码被广泛地应用于无损压缩领域。
Huffman 编码的过程包含两个主要部分:
- 根据输入字符构建 Huffman 树
- 遍历 Huffman 树,并将树的节点分配给字符
上面提到了他的基本原理就是`用短的编码表示出现频率高的字符,用长的编码来表示出现频率低的字符`, 因此首先要做的就是统计字符的出现频率,然后根据统计的频率来构建 Huffman 树(又叫最优二叉树)。
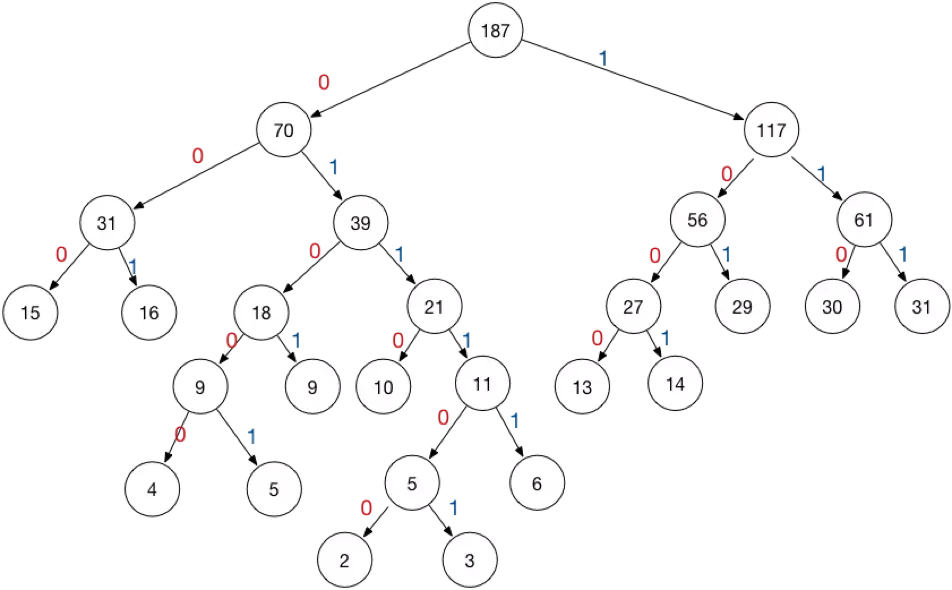
Huffman 树就像是一个堆。真正执行编码的时候,类似字典树,节点不用来编码,节点的路径用来编码.
> 节点的值只是用来构建 Huffman 树
eg:
我们统计的结果如下:
characterfrequencya5b9c12d13e16f45- 将每个元素构造成一个节点,即只有一个元素的树。并构建一个最小堆,包含所有的节点,该算法用了最小堆来作为优先队列。
- `选取两个权值最小的节点`,并添加一个权值为5+9=14的节点,作为他们的父节点。并`更新最小堆`,现在最小堆包含5个节点,其中4个树还是原来的节点,权值为5和9的节点合并为一个。
结果是这样的:
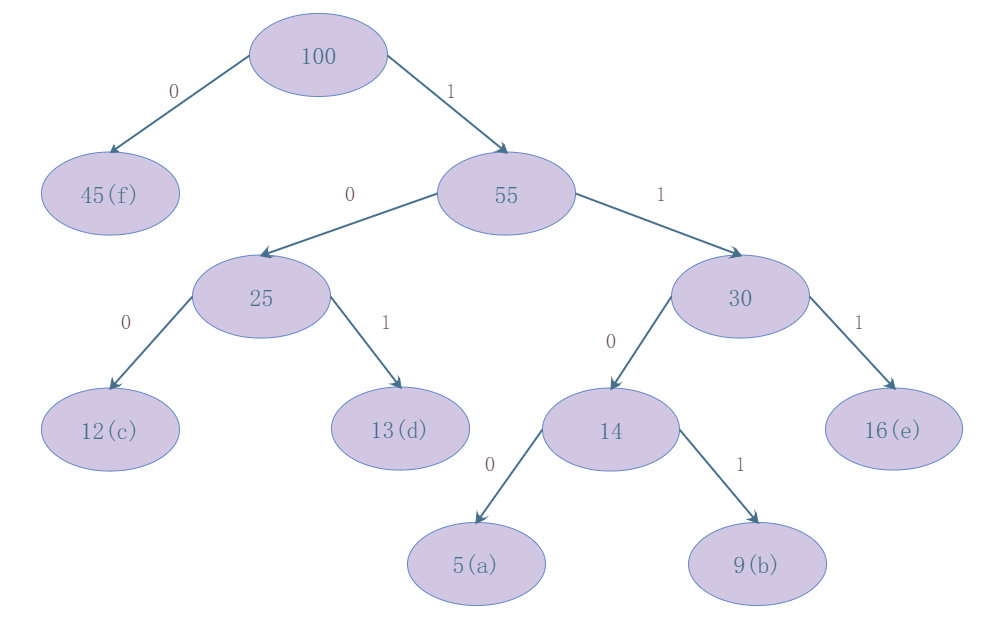
characterfrequencyencodinga51100b91101c12100d13101e16111f450## run-length encode(游程编码)
游程编码是一种比较简单的压缩算法,其基本思想是将重复且连续出现多次的字符使用(连续出现次数,某个字符)来描述。
比如一个字符串:
```
<pre class="calibre18">```
AAAAABBBBCCC
```
```
使用游程编码可以将其描述为:
```
<pre class="calibre18">```
5A4B3C
```
```
5A表示这个地方有5个连续的A,同理4B表示有4个连续的B,3C表示有3个连续的C,其它情况以此类推。
但是实际上情况可能会非常复杂, 如何提取子序列有时候没有看的那么简单,还是上面的例子,我们 有时候可以把`AAAAABBBBCCC`整体看成一个子序列, 更复杂的情况还有很多,这里不做扩展。
对文件进行压缩比较适合的情况是文件内的二进制有大量的连续重复, 一个经典的例子就是具有大面积色块的BMP图像,BMP因为没有压缩, 所以看到的是什么样子存储的时候二进制就是什么样子
> 这也是我们图片倾向于纯色的时候,压缩会有很好的效果
>
> 思考一个问题, 如果我们在CDN上存储两个图片,这两个图片几乎完全一样,我们是否可以进行优化呢? 这虽然是CDN厂商更应该关心的问题,但是这个问题对我们影响依然很大,值得思考
## 总结
游程编码和Huffman都是无损压缩算法,即解压缩过程不会损失原数据任何内容。 实际情况,我们先用游程编码一遍,然后再用 Huffman 再次编码一次。几乎所有的无损压缩格式都用到了它们,比如PNG,GIF,PDF,ZIP等。
对于有损压缩,通常是去除了人类无法识别的颜色,听力频率范围等。也就是说损失了原来的数据。 但由于人类无法识别这部分信息,因此很多情况下都是值得的。这种删除了人类无法感知内容的编码,我们称之为“感知编码”(也许是一个自创的新名词),比如JPEG,MP3等。关于有损压缩不是本文的讨论范围,感兴趣的可以搜素相关资料。
实际上,视频压缩的原理也是类似,只不过视频压缩会用到一些额外的算法,比如“时间冗余”,即仅存储变化的部分,对于不变的部分,存储一次就够了。
## 相关题目
[900.rle-iterator](900.rle-iterator.html)
- Introduction
- 第一章 - 算法专题
- 数据结构
- 基础算法
- 二叉树的遍历
- 动态规划
- 哈夫曼编码和游程编码
- 布隆过滤器
- 字符串问题
- 前缀树专题
- 《贪婪策略》专题
- 《深度优先遍历》专题
- 滑动窗口(思路 + 模板)
- 位运算
- 设计题
- 小岛问题
- 最大公约数
- 并查集
- 前缀和
- 平衡二叉树专题
- 第二章 - 91 天学算法
- 第一期讲义-二分法
- 第一期讲义-双指针
- 第二期
- 第三章 - 精选题解
- 《日程安排》专题
- 《构造二叉树》专题
- 字典序列删除
- 百度的算法面试题 * 祖玛游戏
- 西法的刷题秘籍】一次搞定前缀和
- 字节跳动的算法面试题是什么难度?
- 字节跳动的算法面试题是什么难度?(第二弹)
- 《我是你的妈妈呀》 * 第一期
- 一文带你看懂二叉树的序列化
- 穿上衣服我就不认识你了?来聊聊最长上升子序列
- 你的衣服我扒了 * 《最长公共子序列》
- 一文看懂《最大子序列和问题》
- 第四章 - 高频考题(简单)
- 面试题 17.12. BiNode
- 0001. 两数之和
- 0020. 有效的括号
- 0021. 合并两个有序链表
- 0026. 删除排序数组中的重复项
- 0053. 最大子序和
- 0088. 合并两个有序数组
- 0101. 对称二叉树
- 0104. 二叉树的最大深度
- 0108. 将有序数组转换为二叉搜索树
- 0121. 买卖股票的最佳时机
- 0122. 买卖股票的最佳时机 II
- 0125. 验证回文串
- 0136. 只出现一次的数字
- 0155. 最小栈
- 0167. 两数之和 II * 输入有序数组
- 0169. 多数元素
- 0172. 阶乘后的零
- 0190. 颠倒二进制位
- 0191. 位1的个数
- 0198. 打家劫舍
- 0203. 移除链表元素
- 0206. 反转链表
- 0219. 存在重复元素 II
- 0226. 翻转二叉树
- 0232. 用栈实现队列
- 0263. 丑数
- 0283. 移动零
- 0342. 4的幂
- 0349. 两个数组的交集
- 0371. 两整数之和
- 0437. 路径总和 III
- 0455. 分发饼干
- 0575. 分糖果
- 0874. 模拟行走机器人
- 1260. 二维网格迁移
- 1332. 删除回文子序列
- 第五章 - 高频考题(中等)
- 0002. 两数相加
- 0003. 无重复字符的最长子串
- 0005. 最长回文子串
- 0011. 盛最多水的容器
- 0015. 三数之和
- 0017. 电话号码的字母组合
- 0019. 删除链表的倒数第N个节点
- 0022. 括号生成
- 0024. 两两交换链表中的节点
- 0029. 两数相除
- 0031. 下一个排列
- 0033. 搜索旋转排序数组
- 0039. 组合总和
- 0040. 组合总和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋转图像
- 0049. 字母异位词分组
- 0050. Pow(x, n)
- 0055. 跳跃游戏
- 0056. 合并区间
- 0060. 第k个排列
- 0062. 不同路径
- 0073. 矩阵置零
- 0075. 颜色分类
- 0078. 子集
- 0079. 单词搜索
- 0080. 删除排序数组中的重复项 II
- 0086. 分隔链表
- 0090. 子集 II
- 0091. 解码方法
- 0092. 反转链表 II
- 0094. 二叉树的中序遍历
- 0095. 不同的二叉搜索树 II
- 0096. 不同的二叉搜索树
- 0098. 验证二叉搜索树
- 0102. 二叉树的层序遍历
- 0103. 二叉树的锯齿形层次遍历
- 105. 从前序与中序遍历序列构造二叉树
- 0113. 路径总和 II
- 0129. 求根到叶子节点数字之和
- 0130. 被围绕的区域
- 0131. 分割回文串
- 0139. 单词拆分
- 0144. 二叉树的前序遍历
- 0150. 逆波兰表达式求值
- 0152. 乘积最大子数组
- 0199. 二叉树的右视图
- 0200. 岛屿数量
- 0201. 数字范围按位与
- 0208. 实现 Trie (前缀树)
- 0209. 长度最小的子数组
- 0211. 添加与搜索单词 * 数据结构设计
- 0215. 数组中的第K个最大元素
- 0221. 最大正方形
- 0229. 求众数 II
- 0230. 二叉搜索树中第K小的元素
- 0236. 二叉树的最近公共祖先
- 0238. 除自身以外数组的乘积
- 0240. 搜索二维矩阵 II
- 0279. 完全平方数
- 0309. 最佳买卖股票时机含冷冻期
- 0322. 零钱兑换
- 0328. 奇偶链表
- 0334. 递增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整数拆分
- 0365. 水壶问题
- 0378. 有序矩阵中第K小的元素
- 0380. 常数时间插入、删除和获取随机元素
- 0416. 分割等和子集
- 0445. 两数相加 II
- 0454. 四数相加 II
- 0494. 目标和
- 0516. 最长回文子序列
- 0518. 零钱兑换 II
- 0547. 朋友圈
- 0560. 和为K的子数组
- 0609. 在系统中查找重复文件
- 0611. 有效三角形的个数
- 0718. 最长重复子数组
- 0754. 到达终点数字
- 0785. 判断二分图
- 0820. 单词的压缩编码
- 0875. 爱吃香蕉的珂珂
- 0877. 石子游戏
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序数组
- 0935. 骑士拨号器
- 1011. 在 D 天内送达包裹的能力
- 1014. 最佳观光组合
- 1015. 可被 K 整除的最小整数
- 1019. 链表中的下一个更大节点
- 1020. 飞地的数量
- 1023. 驼峰式匹配
- 1031. 两个非重叠子数组的最大和
- 1104. 二叉树寻路
- 1131.绝对值表达式的最大值
- 1186. 删除一次得到子数组最大和
- 1218. 最长定差子序列
- 1227. 飞机座位分配概率
- 1261. 在受污染的二叉树中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出现次数
- 1310. 子数组异或查询
- 1334. 阈值距离内邻居最少的城市
- 1371.每个元音包含偶数次的最长子字符串
- 第六章 - 高频考题(困难)
- 0004. 寻找两个正序数组的中位数
- 0023. 合并K个升序链表
- 0025. K 个一组翻转链表
- 0030. 串联所有单词的子串
- 0032. 最长有效括号
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱状图中最大的矩形
- 0085. 最大矩形
- 0124. 二叉树中的最大路径和
- 0128. 最长连续序列
- 0145. 二叉树的后序遍历
- 0212. 单词搜索 II
- 0239. 滑动窗口最大值
- 0295. 数据流的中位数
- 0301. 删除无效的括号
- 0312. 戳气球
- 0335. 路径交叉
- 0460. LFU缓存
- 0472. 连接词
- 0488. 祖玛游戏
- 0493. 翻转对
- 0887. 鸡蛋掉落
- 0895. 最大频率栈
- 1032. 字符流
- 1168. 水资源分配优化
- 1449. 数位成本和为目标值的最大数字
- 后序