# 字典序列删除
# 一招吃遍力扣四道题,妈妈再也不用担心我被套路啦~
我花了几天时间,从力扣中精选了四道相同思想的题目,来帮助大家解套,如果觉得文章对你有用,记得点赞分享,让我看到你的认可,有动力继续做下去。
这就是接下来要给大家讲的四个题,其中 1081 和 316 题只是换了说法而已。
- [316. 去除重复字母](https://leetcode-cn.com/problems/remove-duplicate-letters/)(困难)
- [321. 拼接最大数](https://leetcode-cn.com/problems/create-maximum-number/)(困难)
- [402. 移掉 K 位数字](https://leetcode-cn.com/problems/remove-k-digits/)(中等)
- [1081. 不同字符的最小子序列](https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters/)(中等)
## 402. 移掉 K 位数字(中等)
我们从一个简单的问题入手,识别一下这种题的基本形式和套路,为之后的三道题打基础。
### 题目描述
```
<pre class="calibre18">```
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小。
注意:
num 的长度小于 10002 且 ≥ k。
num 不会包含任何前导零。
示例 1 :
输入: num = "1432219", k = 3
输出: "1219"
解释: 移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219。
示例 2 :
输入: num = "10200", k = 1
输出: "200"
解释: 移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。
示例 3 :
输入: num = "10", k = 2
输出: "0"
解释: 从原数字移除所有的数字,剩余为空就是 0。
```
```
### 前置知识
- 数学
### 思路
这道题让我们从一个字符串数字中删除 k 个数字,使得剩下的数最小。也就说,我们要保持原来的数字的相对位置不变。
以题目中的 `num = 1432219, k = 3` 为例,我们需要返回一个长度为 4 的字符串,问题在于: 我们怎么才能求出这四个位置依次是什么呢?
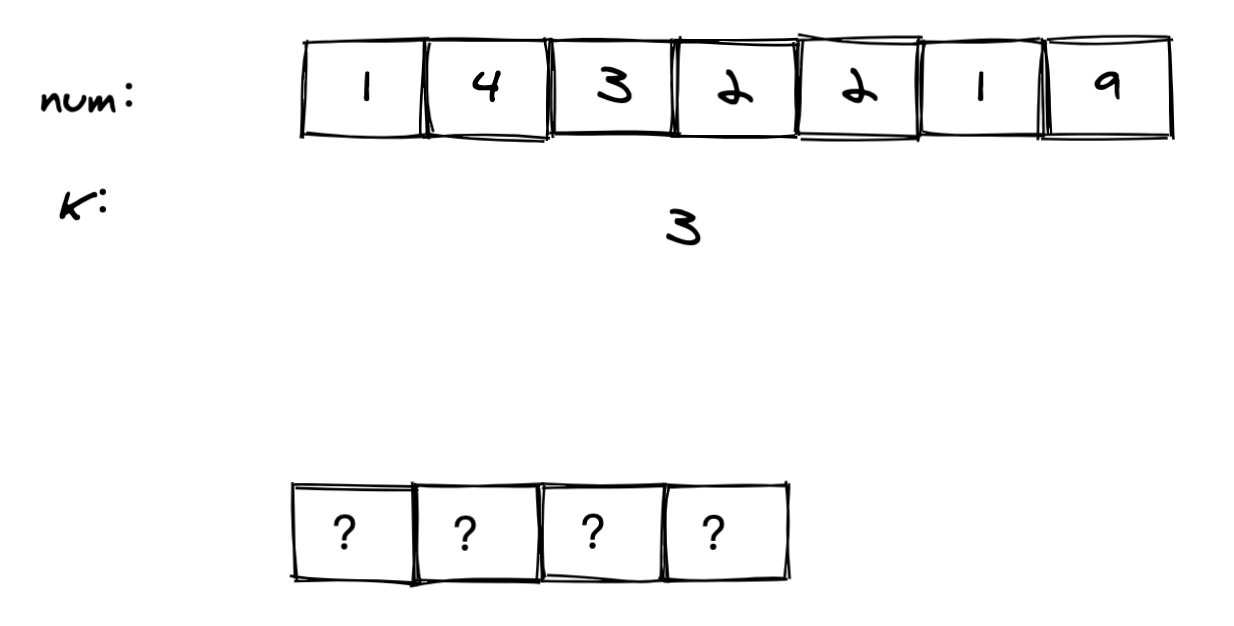
(图 1)
暴力法的话,我们需要枚举`C_n^(n - k)` 种序列(其中 n 为数字长度),并逐个比较最大。这个时间复杂度是指数级别的,必须进行优化。
一个思路是:
- 从左到右遍历
- 对于每一个遍历到的元素,我们决定是**丢弃**还是**保留**
问题的关键是:我们怎么知道,一个元素是应该保留还是丢弃呢?
这里有一个前置知识:**对于两个数 123a456 和 123b456,如果 a > b, 那么数字 123a456 大于 数字 123b456,否则数字 123a456 小于等于数字 123b456**。也就说,两个**相同位数**的数字大小关系取决于第一个不同的数的大小。
因此我们的思路就是:
- 从左到右遍历
- 对于遍历到的元素,我们选择保留。
- 但是我们可以选择性丢弃前面相邻的元素。
- 丢弃与否的依据如上面的前置知识中阐述中的方法。
以题目中的 `num = 1432219, k = 3` 为例的图解过程如下:
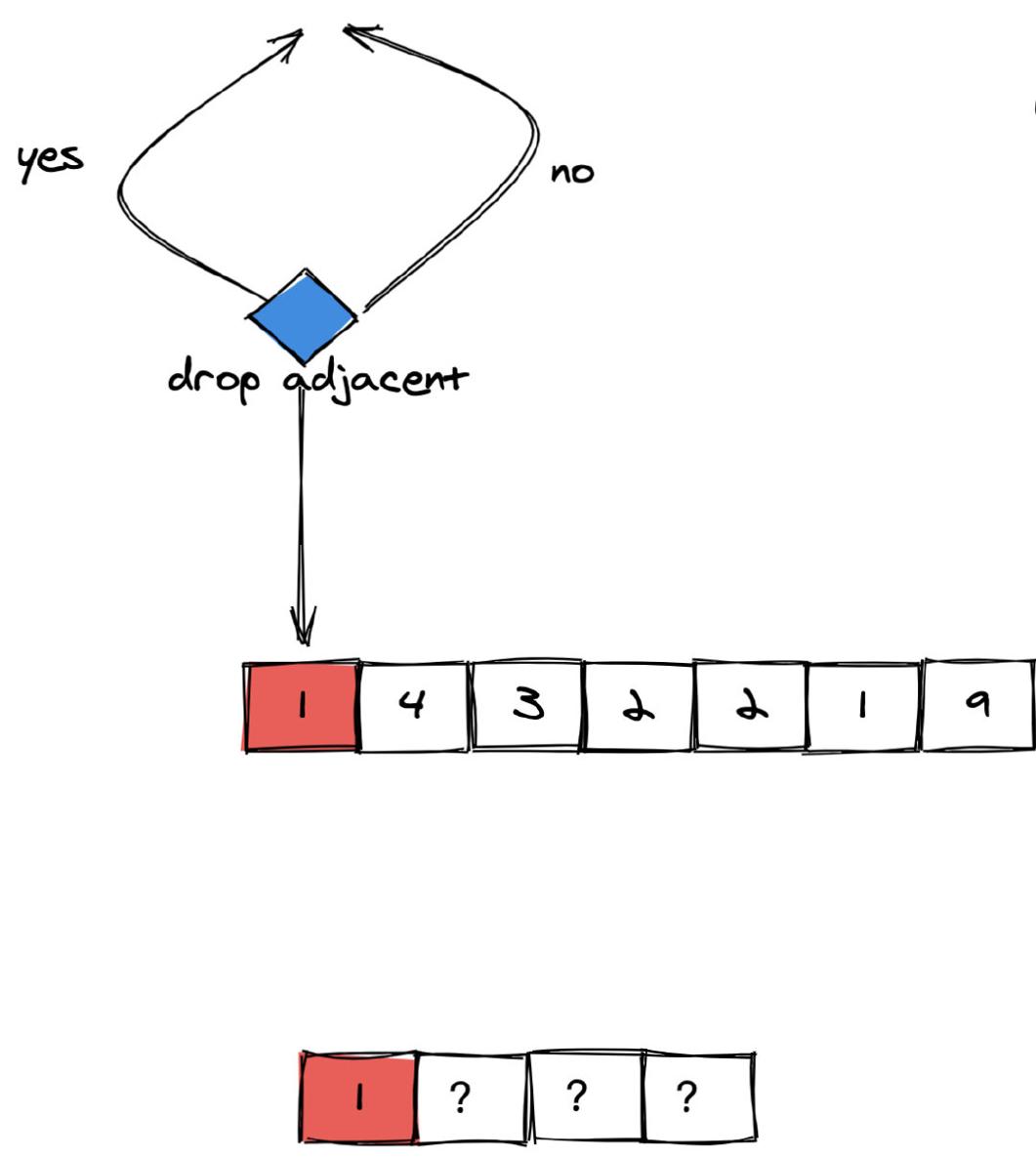
(图 2)
由于没有左侧相邻元素,因此**没办法丢弃**。
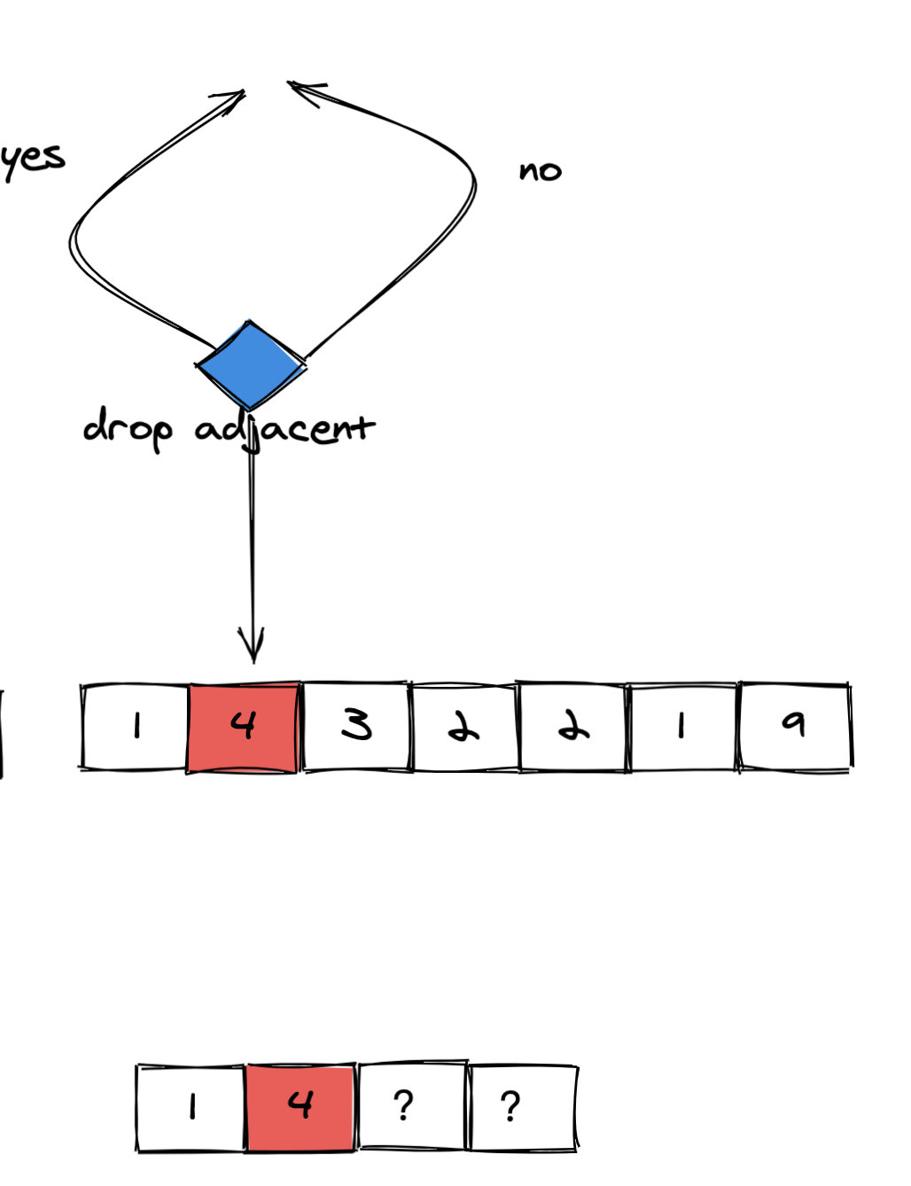
(图 3)
由于 4 比左侧相邻的 1 大。如果选择丢弃左侧的 1,那么会使得剩下的数字更大(开头的数从 1 变成了 4)。因此我们仍然选择**不丢弃**。
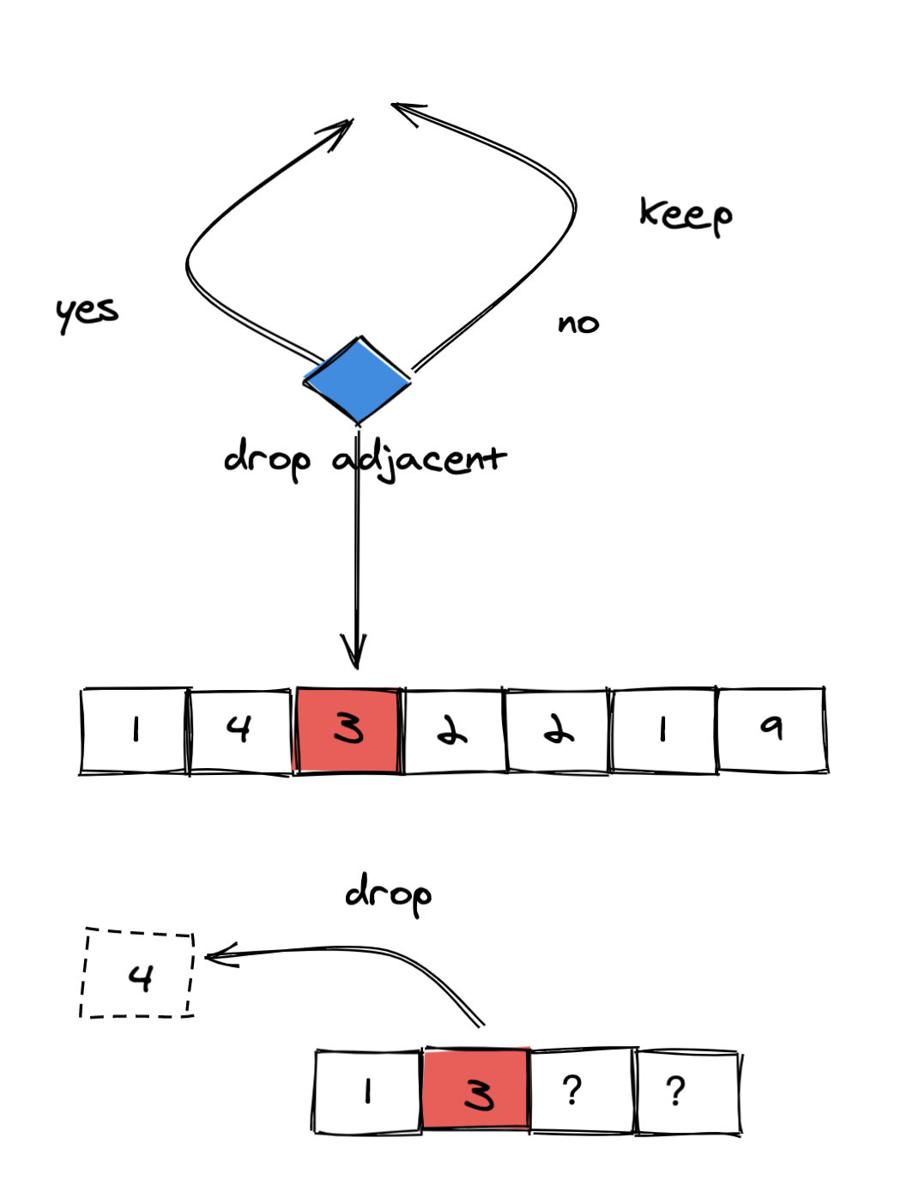
(图 4)
由于 3 比左侧相邻的 4 小。 如果选择丢弃左侧的 4,那么会使得剩下的数字更小(开头的数从 4 变成了 3)。因此我们选择**丢弃**。
。。。
后面的思路类似,我就不继续分析啦。
然而需要注意的是,如果给定的数字是一个单调递增的数字,那么我们的算法会永远**选择不丢弃**。这个题目中要求的,我们要永远确保**丢弃** k 个矛盾。
一个简单的思路就是:
- 每次丢弃一次,k 减去 1。当 k 减到 0 ,我们可以提前终止遍历。
- 而当遍历完成,如果 k 仍然大于 0。不妨假设最终还剩下 x 个需要丢弃,那么我们需要选择删除末尾 x 个元素。
上面的思路可行,但是稍显复杂。
(图 5)
我们需要把思路逆转过来。刚才我的关注点一直是**丢弃**,题目要求我们丢弃 k 个。反过来说,不就是让我们保留 n−kn - kn−k 个元素么?其中 n 为数字长度。 那么我们只需要按照上面的方法遍历完成之后,再截取前**n - k**个元素即可。
按照上面的思路,我们来选择数据结构。由于我们需要**保留**和**丢弃相邻**的元素,因此使用栈这种在一端进行添加和删除的数据结构是再合适不过了,我们来看下代码实现。
### 代码(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span><span class="hljs-params">(object)</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">removeKdigits</span><span class="hljs-params">(self, num, k)</span>:</span>
stack = []
remain = len(num) - k
<span class="hljs-keyword">for</span> digit <span class="hljs-keyword">in</span> num:
<span class="hljs-keyword">while</span> k <span class="hljs-keyword">and</span> stack <span class="hljs-keyword">and</span> stack[<span class="hljs-params">-1</span>] > digit:
stack.pop()
k -= <span class="hljs-params">1</span>
stack.append(digit)
<span class="hljs-keyword">return</span> <span class="hljs-string">''</span>.join(stack[:remain]).lstrip(<span class="hljs-string">'0'</span>) <span class="hljs-keyword">or</span> <span class="hljs-string">'0'</span>
```
```
***复杂度分析***
- 时间复杂度:虽然内层还有一个 while 循环,但是由于每个数字最多仅会入栈出栈一次,因此时间复杂度仍然为 O(N)O(N)O(N),其中 NNN 为数字长度。
- 空间复杂度:我们使用了额外的栈来存储数字,因此空间复杂度为 O(N)O(N)O(N),其中 NNN 为数字长度。
> 提示: 如果题目改成求删除 k 个字符之后的最大数,我们只需要将 stack\[-1\] > digit 中的大于号改成小于号即可。
## 316. 去除重复字母(困难)
### 题目描述
```
<pre class="calibre18">```
给你一个仅包含小写字母的字符串,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
示例 1:
输入: "bcabc"
输出: "abc"
示例 2:
输入: "cbacdcbc"
输出: "acdb"
```
```
## 前置知识
- 字典序
- 数学
### 思路
与上面题目不同,这道题没有一个全局的删除次数 k。而是对于每一个在字符串 s 中出现的字母 c 都有一个 k 值。这个 k 是 c 出现次数 - 1。
沿用上面的知识的话,我们首先要做的就是计算每一个字符的 k,可以用一个字典来描述这种关系,其中 key 为 字符 c,value 为其出现的次数。
具体算法:
- 建立一个字典。其中 key 为 字符 c,value 为其出现的剩余次数。
- 从左往右遍历字符串,每次遍历到一个字符,其剩余出现次数 - 1.
- 对于每一个字符,如果其对应的剩余出现次数大于 1,我们**可以**选择丢弃(也可以选择不丢弃),否则不可以丢弃。
- 是否丢弃的标准和上面题目类似。如果栈中相邻的元素字典序更大,那么我们选择丢弃相邻的栈中的元素。
还记得上面题目的边界条件么?如果栈中剩下的元素大于 n−kn - kn−k,我们选择截取前 n−kn - kn−k 个数字。然而本题中的 k 是分散在各个字符中的,因此这种思路不可行的。
不过不必担心。由于题目是要求只出现一次。我们可以在遍历的时候简单地判断其是否在栈上即可。
代码:
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">removeDuplicateLetters</span><span class="hljs-params">(self, s)</span> -> int:</span>
stack = []
remain_counter = collections.Counter(s)
<span class="hljs-keyword">for</span> c <span class="hljs-keyword">in</span> s:
<span class="hljs-keyword">if</span> c <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> stack:
<span class="hljs-keyword">while</span> stack <span class="hljs-keyword">and</span> c < stack[<span class="hljs-params">-1</span>] <span class="hljs-keyword">and</span> remain_counter[stack[<span class="hljs-params">-1</span>]] > <span class="hljs-params">0</span>:
stack.pop()
stack.append(c)
remain_counter[c] -= <span class="hljs-params">1</span>
<span class="hljs-keyword">return</span> <span class="hljs-string">''</span>.join(stack)
```
```
***复杂度分析***
- 时间复杂度:由于判断当前字符是否在栈上存在需要 O(N)O(N)O(N) 的时间,因此总的时间复杂度就是 O(N2)O(N ^ 2)O(N2),其中 NNN 为字符串长度。
- 空间复杂度:我们使用了额外的栈来存储数字,因此空间复杂度为 O(N)O(N)O(N),其中 NNN 为字符串长度。
查询给定字符是否在一个序列中存在的方法。根本上来说,有两种可能:
- 有序序列: 可以二分法,时间复杂度大致是 O(N)O(N)O(N)。
- 无序序列: 可以使用遍历的方式,最坏的情况下时间复杂度为 O(N)O(N)O(N)。我们也可以使用空间换时间的方式,使用 NNN的空间 换取 O(1)O(1)O(1)的时间复杂度。
由于本题中的 stack 并不是有序的,因此我们的优化点考虑空间换时间。而由于每种字符仅可以出现一次,这里使用 hashset 即可。
### 代码(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">removeDuplicateLetters</span><span class="hljs-params">(self, s)</span> -> int:</span>
stack = []
seen = set()
remain_counter = collections.Counter(s)
<span class="hljs-keyword">for</span> c <span class="hljs-keyword">in</span> s:
<span class="hljs-keyword">if</span> c <span class="hljs-keyword">not</span> <span class="hljs-keyword">in</span> seen:
<span class="hljs-keyword">while</span> stack <span class="hljs-keyword">and</span> c < stack[<span class="hljs-params">-1</span>] <span class="hljs-keyword">and</span> remain_counter[stack[<span class="hljs-params">-1</span>]] > <span class="hljs-params">0</span>:
seen.discard(stack.pop())
seen.add(c)
stack.append(c)
remain_counter[c] -= <span class="hljs-params">1</span>
<span class="hljs-keyword">return</span> <span class="hljs-string">''</span>.join(stack)
```
```
***复杂度分析***
- 时间复杂度:O(N)O(N)O(N),其中 NNN 为字符串长度。
- 空间复杂度:我们使用了额外的栈和 hashset,因此空间复杂度为 O(N)O(N)O(N),其中 NNN 为字符串长度。
> LeetCode 《1081. 不同字符的最小子序列》 和本题一样,不再赘述。
## 321. 拼接最大数(困难)
### 题目描述
```
<pre class="calibre18">```
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
示例 1:
输入:
nums1 = [3, 4, 6, 5]
nums2 = [9, 1, 2, 5, 8, 3]
k = 5
输出:
[9, 8, 6, 5, 3]
示例 2:
输入:
nums1 = [6, 7]
nums2 = [6, 0, 4]
k = 5
输出:
[6, 7, 6, 0, 4]
示例 3:
输入:
nums1 = [3, 9]
nums2 = [8, 9]
k = 3
输出:
[9, 8, 9]
```
```
### 前置知识
- 分治
- 数学
### 思路
和第一道题类似,只不不过这一次是两个**数组**,而不是一个,并且是求最大数。
最大最小是无关紧要的,关键在于是两个数组,并且要求从两个数组选取的元素个数加起来一共是 k。
然而在一个数组中取 k 个数字,并保持其最小(或者最大),我们已经会了。但是如果问题扩展到两个,会有什么变化呢?
实际上,问题本质并没有发生变化。 假设我们从 nums1 中取了 k1 个,从 num2 中取了 k2 个,其中 k1 + k2 = k。而 k1 和 k2 这 两个子问题我们是会解决的。由于这两个子问题是相互独立的,因此我们只需要分别求解,然后将结果合并即可。
假如 k1 和 k2 个数字,已经取出来了。那么剩下要做的就是将这个长度分别为 k1 和 k2 的数字,合并成一个长度为 k 的数组合并成一个最大的数组。
以题目的 `nums1 = [3, 4, 6, 5] nums2 = [9, 1, 2, 5, 8, 3] k = 5` 为例。 假如我们从 num1 中取出 1 个数字,那么就要从 nums2 中取出 4 个数字。
运用第一题的方法,我们计算出应该取 nums1 的 \[6\],并取 nums2 的 \[9,5,8,3\]。 如何将 \[6\] 和 \[9,5,8,3\],使得数字尽可能大,并且保持相对位置不变呢?
实际上这个过程有点类似`归并排序`中的**治**,而上面我们分别计算 num1 和 num2 的最大数的过程类似`归并排序`中的**分**。
(图 6)
代码:
> 我们将从 num1 中挑选的 k1 个数组成的数组称之为 A,将从 num2 中挑选的 k2 个数组成的数组称之为 B,
```
<pre class="calibre18">```
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">merge</span><span class="hljs-params">(A, B)</span>:</span>
ans = []
<span class="hljs-keyword">while</span> A <span class="hljs-keyword">or</span> B:
bigger = A <span class="hljs-keyword">if</span> A > B <span class="hljs-keyword">else</span> B
ans.append(bigger[<span class="hljs-params">0</span>])
bigger.pop(<span class="hljs-params">0</span>)
<span class="hljs-keyword">return</span> ans
```
```
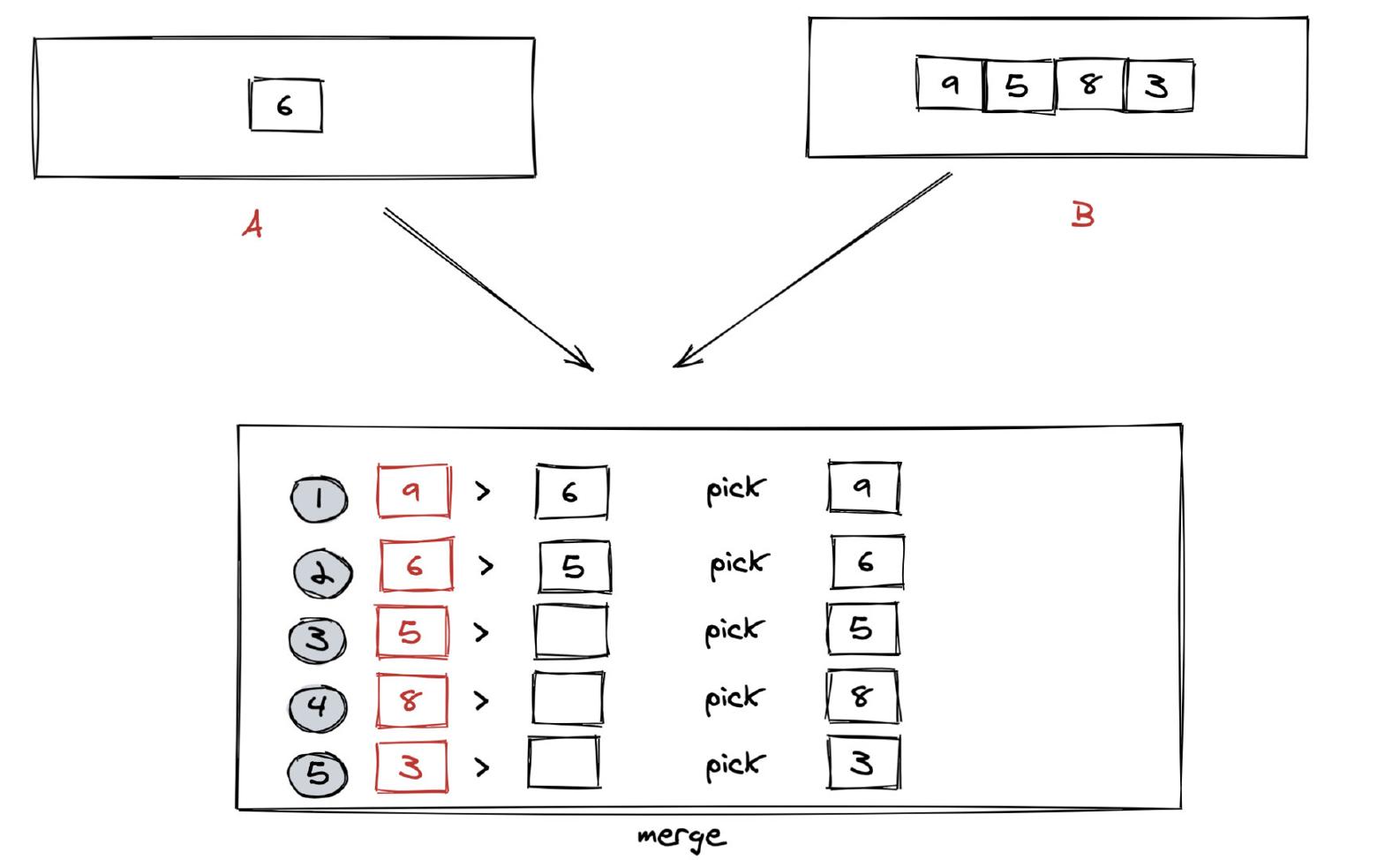
这里需要说明一下。 在很多编程语言中:**如果 A 和 B 是两个数组,当前仅当 A 的首个元素字典序大于 B 的首个元素,A > B 返回 true,否则返回 false**。
比如:
```
<pre class="calibre18">```
A = [1,2]
B = [2]
A < B # True
A = [1,2]
B = [1,2,3]
A < B # False
```
```
以合并 \[6\] 和 \[9,5,8,3\] 为例,图解过程如下:
(图 7)
具体算法:
- 从 nums1 中 取 min(i,len(nums1))min(i, len(nums1))min(i,len(nums1)) 个数形成新的数组 A(取的逻辑同第一题),其中 i 等于 0,1,2, ... k。
- 从 nums2 中 对应取 min(j,len(nums2))min(j, len(nums2))min(j,len(nums2)) 个数形成新的数组 B(取的逻辑同第一题),其中 j 等于 k - i。
- 将 A 和 B 按照上面的 merge 方法合并
- 上面我们暴力了 k 种组合情况,我们只需要将 k 种情况取出最大值即可。
### 代码(Python)
```
<pre class="calibre18">```
<span class="hljs-class"><span class="hljs-keyword">class</span> <span class="hljs-title">Solution</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">maxNumber</span><span class="hljs-params">(self, nums1, nums2, k)</span>:</span>
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">pick_max</span><span class="hljs-params">(nums, k)</span>:</span>
stack = []
drop = len(nums) - k
<span class="hljs-keyword">for</span> num <span class="hljs-keyword">in</span> nums:
<span class="hljs-keyword">while</span> drop <span class="hljs-keyword">and</span> stack <span class="hljs-keyword">and</span> stack[<span class="hljs-params">-1</span>] < num:
stack.pop()
drop -= <span class="hljs-params">1</span>
stack.append(num)
<span class="hljs-keyword">return</span> stack[:k]
<span class="hljs-function"><span class="hljs-keyword">def</span> <span class="hljs-title">merge</span><span class="hljs-params">(A, B)</span>:</span>
ans = []
<span class="hljs-keyword">while</span> A <span class="hljs-keyword">or</span> B:
bigger = A <span class="hljs-keyword">if</span> A > B <span class="hljs-keyword">else</span> B
ans.append(bigger[<span class="hljs-params">0</span>])
bigger.pop(<span class="hljs-params">0</span>)
<span class="hljs-keyword">return</span> ans
<span class="hljs-keyword">return</span> max(merge(pick_max(nums1, i), pick_max(nums2, k-i)) <span class="hljs-keyword">for</span> i <span class="hljs-keyword">in</span> range(k+<span class="hljs-params">1</span>) <span class="hljs-keyword">if</span> i <= len(nums1) <span class="hljs-keyword">and</span> k-i <= len(nums2))
```
```
***复杂度分析***
- 时间复杂度:pick\_max 的时间复杂度为 O(M+N)O(M + N)O(M+N) ,其中 MMM 为 nums1 的长度,NNN 为 nums2 的长度。 merge 的时间复杂度为 O(k)O(k)O(k),再加上外层遍历所有的 k 中可能性。因此总的时间复杂度为 O(k2∗(M+N))O(k^2 \* (M + N))O(k2∗(M+N))。
- 空间复杂度:我们使用了额外的 stack 和 ans 数组,因此空间复杂度为 O(max(M,N,k))O(max(M, N, k))O(max(M,N,k)),其中 MMM 为 nums1 的长度,NNN 为 nums2 的长度。
## 总结
这四道题都是删除或者保留若干个字符,使得剩下的数字最小(或最大)或者字典序最小(或最大)。而解决问题的前提是要有一定**数学前提**。而基于这个数学前提,我们贪心地删除栈中相邻的字符。如果你会了这个套路,那么这四个题目应该都可以轻松解决。
`316. 去除重复字母(困难)`,我们使用 hashmap 代替了数组的遍历查找,属于典型的空间换时间方式,可以认识到数据结构的灵活使用是多么的重要。背后的思路是怎么样的?为什么想到空间换时间的方式,我在文中也进行了详细的说明,这都是值得大家思考的问题。然而实际上,这些题目中使用的栈也都是空间换时间的思想。大家下次碰到**需要空间换取时间**的场景,是否能够想到本文给大家介绍的**栈**和**哈希表**呢?
`321. 拼接最大数(困难)`则需要我们能够对问题进行分解,这绝对不是一件简单的事情。但是对难以解决的问题进行分解是一种很重要的技能,希望大家能够通过这道题加深这种**分治**思想的理解。 大家可以结合我之前写过的几个题解练习一下,它们分别是:
- [【简单易懂】归并排序(Python)](https://leetcode-cn.com/problems/shu-zu-zhong-de-ni-xu-dui-lcof/solution/jian-dan-yi-dong-gui-bing-pai-xu-python-by-azl3979/)
- [一文看懂《最大子序列和问题》](https://lucifer.ren/blog/2019/12/11/LSS/)
更多题解可以访问我的 LeetCode 题解仓库:<https://github.com/azl397985856/leetcode> 。 目前已经 37K star 啦。
大家也可以关注我的公众号《力扣加加》获取更多更新鲜的 LeetCode 题解

- Introduction
- 第一章 - 算法专题
- 数据结构
- 基础算法
- 二叉树的遍历
- 动态规划
- 哈夫曼编码和游程编码
- 布隆过滤器
- 字符串问题
- 前缀树专题
- 《贪婪策略》专题
- 《深度优先遍历》专题
- 滑动窗口(思路 + 模板)
- 位运算
- 设计题
- 小岛问题
- 最大公约数
- 并查集
- 前缀和
- 平衡二叉树专题
- 第二章 - 91 天学算法
- 第一期讲义-二分法
- 第一期讲义-双指针
- 第二期
- 第三章 - 精选题解
- 《日程安排》专题
- 《构造二叉树》专题
- 字典序列删除
- 百度的算法面试题 * 祖玛游戏
- 西法的刷题秘籍】一次搞定前缀和
- 字节跳动的算法面试题是什么难度?
- 字节跳动的算法面试题是什么难度?(第二弹)
- 《我是你的妈妈呀》 * 第一期
- 一文带你看懂二叉树的序列化
- 穿上衣服我就不认识你了?来聊聊最长上升子序列
- 你的衣服我扒了 * 《最长公共子序列》
- 一文看懂《最大子序列和问题》
- 第四章 - 高频考题(简单)
- 面试题 17.12. BiNode
- 0001. 两数之和
- 0020. 有效的括号
- 0021. 合并两个有序链表
- 0026. 删除排序数组中的重复项
- 0053. 最大子序和
- 0088. 合并两个有序数组
- 0101. 对称二叉树
- 0104. 二叉树的最大深度
- 0108. 将有序数组转换为二叉搜索树
- 0121. 买卖股票的最佳时机
- 0122. 买卖股票的最佳时机 II
- 0125. 验证回文串
- 0136. 只出现一次的数字
- 0155. 最小栈
- 0167. 两数之和 II * 输入有序数组
- 0169. 多数元素
- 0172. 阶乘后的零
- 0190. 颠倒二进制位
- 0191. 位1的个数
- 0198. 打家劫舍
- 0203. 移除链表元素
- 0206. 反转链表
- 0219. 存在重复元素 II
- 0226. 翻转二叉树
- 0232. 用栈实现队列
- 0263. 丑数
- 0283. 移动零
- 0342. 4的幂
- 0349. 两个数组的交集
- 0371. 两整数之和
- 0437. 路径总和 III
- 0455. 分发饼干
- 0575. 分糖果
- 0874. 模拟行走机器人
- 1260. 二维网格迁移
- 1332. 删除回文子序列
- 第五章 - 高频考题(中等)
- 0002. 两数相加
- 0003. 无重复字符的最长子串
- 0005. 最长回文子串
- 0011. 盛最多水的容器
- 0015. 三数之和
- 0017. 电话号码的字母组合
- 0019. 删除链表的倒数第N个节点
- 0022. 括号生成
- 0024. 两两交换链表中的节点
- 0029. 两数相除
- 0031. 下一个排列
- 0033. 搜索旋转排序数组
- 0039. 组合总和
- 0040. 组合总和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋转图像
- 0049. 字母异位词分组
- 0050. Pow(x, n)
- 0055. 跳跃游戏
- 0056. 合并区间
- 0060. 第k个排列
- 0062. 不同路径
- 0073. 矩阵置零
- 0075. 颜色分类
- 0078. 子集
- 0079. 单词搜索
- 0080. 删除排序数组中的重复项 II
- 0086. 分隔链表
- 0090. 子集 II
- 0091. 解码方法
- 0092. 反转链表 II
- 0094. 二叉树的中序遍历
- 0095. 不同的二叉搜索树 II
- 0096. 不同的二叉搜索树
- 0098. 验证二叉搜索树
- 0102. 二叉树的层序遍历
- 0103. 二叉树的锯齿形层次遍历
- 105. 从前序与中序遍历序列构造二叉树
- 0113. 路径总和 II
- 0129. 求根到叶子节点数字之和
- 0130. 被围绕的区域
- 0131. 分割回文串
- 0139. 单词拆分
- 0144. 二叉树的前序遍历
- 0150. 逆波兰表达式求值
- 0152. 乘积最大子数组
- 0199. 二叉树的右视图
- 0200. 岛屿数量
- 0201. 数字范围按位与
- 0208. 实现 Trie (前缀树)
- 0209. 长度最小的子数组
- 0211. 添加与搜索单词 * 数据结构设计
- 0215. 数组中的第K个最大元素
- 0221. 最大正方形
- 0229. 求众数 II
- 0230. 二叉搜索树中第K小的元素
- 0236. 二叉树的最近公共祖先
- 0238. 除自身以外数组的乘积
- 0240. 搜索二维矩阵 II
- 0279. 完全平方数
- 0309. 最佳买卖股票时机含冷冻期
- 0322. 零钱兑换
- 0328. 奇偶链表
- 0334. 递增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整数拆分
- 0365. 水壶问题
- 0378. 有序矩阵中第K小的元素
- 0380. 常数时间插入、删除和获取随机元素
- 0416. 分割等和子集
- 0445. 两数相加 II
- 0454. 四数相加 II
- 0494. 目标和
- 0516. 最长回文子序列
- 0518. 零钱兑换 II
- 0547. 朋友圈
- 0560. 和为K的子数组
- 0609. 在系统中查找重复文件
- 0611. 有效三角形的个数
- 0718. 最长重复子数组
- 0754. 到达终点数字
- 0785. 判断二分图
- 0820. 单词的压缩编码
- 0875. 爱吃香蕉的珂珂
- 0877. 石子游戏
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序数组
- 0935. 骑士拨号器
- 1011. 在 D 天内送达包裹的能力
- 1014. 最佳观光组合
- 1015. 可被 K 整除的最小整数
- 1019. 链表中的下一个更大节点
- 1020. 飞地的数量
- 1023. 驼峰式匹配
- 1031. 两个非重叠子数组的最大和
- 1104. 二叉树寻路
- 1131.绝对值表达式的最大值
- 1186. 删除一次得到子数组最大和
- 1218. 最长定差子序列
- 1227. 飞机座位分配概率
- 1261. 在受污染的二叉树中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出现次数
- 1310. 子数组异或查询
- 1334. 阈值距离内邻居最少的城市
- 1371.每个元音包含偶数次的最长子字符串
- 第六章 - 高频考题(困难)
- 0004. 寻找两个正序数组的中位数
- 0023. 合并K个升序链表
- 0025. K 个一组翻转链表
- 0030. 串联所有单词的子串
- 0032. 最长有效括号
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱状图中最大的矩形
- 0085. 最大矩形
- 0124. 二叉树中的最大路径和
- 0128. 最长连续序列
- 0145. 二叉树的后序遍历
- 0212. 单词搜索 II
- 0239. 滑动窗口最大值
- 0295. 数据流的中位数
- 0301. 删除无效的括号
- 0312. 戳气球
- 0335. 路径交叉
- 0460. LFU缓存
- 0472. 连接词
- 0488. 祖玛游戏
- 0493. 翻转对
- 0887. 鸡蛋掉落
- 0895. 最大频率栈
- 1032. 字符流
- 1168. 水资源分配优化
- 1449. 数位成本和为目标值的最大数字
- 后序