# 布隆过滤器
## 场景
假设你现在要处理这样一个问题,你有一个网站并且拥有`很多`访客,每当有用户访问时,你想知道这个ip是不是第一次访问你的网站。
### hashtable 可以么
一个显而易见的答案是将所有的 IP 用 hashtable 存起来,每次访问都去 hashtable 中取,然后判断即可。但是题目说了网站有`很多`访客, 假如有10亿个用户访问过,假设 IP 是 IPV4, 那么每个 IP 的长度是 4 byte,那么你一共需要4 \* 1000000000 = 4000000000Bytes = 4G 。
如果是判断 URL 黑名单,由于每个 URL 会更长(可能远大于上面 IPV4 地址的 4 byte),那么需要的空间可能会远远大于你的期望。
### bit
另一个稍微难想到的解法是bit, 我们知道bit有 0 和 1 两种状态,那么用来表示**存在**与**不存在**再合适不过了。
假如有 10 亿个 IP,就可以用 10 亿个 bit 来存储,那么你一共需要 1 \* 1000000000 = (4000000000 / 8) Bytes = 128M, 变为原来的1/32, 如果是存储URL这种更长的字符串,效率会更高。 问题是,我们怎么把 IPV4 和 bit 的位置关联上呢?
比如`192.168.1.1` 应该是用第几位表示,`10.18.1.1` 应该是用第几位表示呢? 答案是使用哈希函数。
基于这种想法,我们只需要两个操作,set(ip) 和 has(ip),以及一个内置函数 hash(ip) 用于将 IP 映射到 bit 表。
这样做有两个非常致命的缺点:
1. 当样本分布极度不均匀的时候,会造成很大空间上的浪费
> 我们可以通过优化散列函数来解决
1. 当元素不是整型(比如URL)的时候,BitSet就不适用了
> 我们还是可以使用散列函数来解决, 甚至可以多hash几次
### 布隆过滤器
布隆过滤器其实就是`bit + 多个散列函数`。k 次 hash(ip) 会生成多个索引,并将其 k 个索引位置的二进制置为 1。 如果经过 k 个索引位置的值都为 1,那么认为其**可能存在**(因为有冲突的可能)。 如果有一个不为1,那么**一定不存在**(一个值经过散列函数得到的值一定是唯一的),这也是布隆过滤器的一个重要特点。也就是说布隆过滤器回答了:**可能存在** 和 **一定不存在** 的问题。
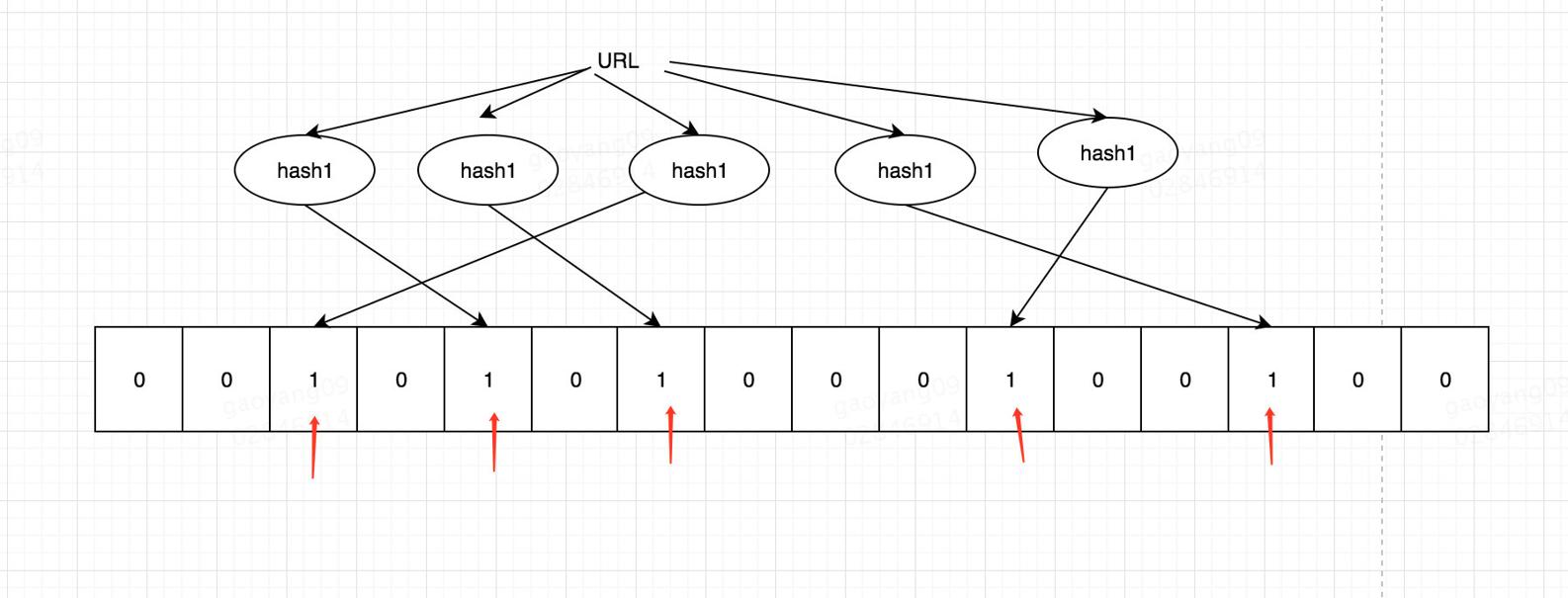
从上图可以看出, 布隆过滤器本质上是由**一个很长的二进制向量**和**多个哈希函数**组成。
由于没有 hashtable 的100% 可靠性,因此这本质上是一种**可靠性换取空间的做法**。除了可靠性,布隆过滤器删除起来也比较麻烦。
### 布隆过滤器的应用
1. 网络爬虫
判断某个URL是否已经被爬取过
1. K-V数据库 判断某个key是否存在
比如 Hbase 的每个 Region 中都包含一个 BloomFilter,用于在查询时快速判断某个 key 在该 region 中是否存在。
1. 钓鱼网站识别
浏览器有时候会警告用户,访问的网站很可能是钓鱼网站,用的就是这种技术
> 从这个算法大家可以对 tradeoff(取舍) 有更入的理解。
- Introduction
- 第一章 - 算法专题
- 数据结构
- 基础算法
- 二叉树的遍历
- 动态规划
- 哈夫曼编码和游程编码
- 布隆过滤器
- 字符串问题
- 前缀树专题
- 《贪婪策略》专题
- 《深度优先遍历》专题
- 滑动窗口(思路 + 模板)
- 位运算
- 设计题
- 小岛问题
- 最大公约数
- 并查集
- 前缀和
- 平衡二叉树专题
- 第二章 - 91 天学算法
- 第一期讲义-二分法
- 第一期讲义-双指针
- 第二期
- 第三章 - 精选题解
- 《日程安排》专题
- 《构造二叉树》专题
- 字典序列删除
- 百度的算法面试题 * 祖玛游戏
- 西法的刷题秘籍】一次搞定前缀和
- 字节跳动的算法面试题是什么难度?
- 字节跳动的算法面试题是什么难度?(第二弹)
- 《我是你的妈妈呀》 * 第一期
- 一文带你看懂二叉树的序列化
- 穿上衣服我就不认识你了?来聊聊最长上升子序列
- 你的衣服我扒了 * 《最长公共子序列》
- 一文看懂《最大子序列和问题》
- 第四章 - 高频考题(简单)
- 面试题 17.12. BiNode
- 0001. 两数之和
- 0020. 有效的括号
- 0021. 合并两个有序链表
- 0026. 删除排序数组中的重复项
- 0053. 最大子序和
- 0088. 合并两个有序数组
- 0101. 对称二叉树
- 0104. 二叉树的最大深度
- 0108. 将有序数组转换为二叉搜索树
- 0121. 买卖股票的最佳时机
- 0122. 买卖股票的最佳时机 II
- 0125. 验证回文串
- 0136. 只出现一次的数字
- 0155. 最小栈
- 0167. 两数之和 II * 输入有序数组
- 0169. 多数元素
- 0172. 阶乘后的零
- 0190. 颠倒二进制位
- 0191. 位1的个数
- 0198. 打家劫舍
- 0203. 移除链表元素
- 0206. 反转链表
- 0219. 存在重复元素 II
- 0226. 翻转二叉树
- 0232. 用栈实现队列
- 0263. 丑数
- 0283. 移动零
- 0342. 4的幂
- 0349. 两个数组的交集
- 0371. 两整数之和
- 0437. 路径总和 III
- 0455. 分发饼干
- 0575. 分糖果
- 0874. 模拟行走机器人
- 1260. 二维网格迁移
- 1332. 删除回文子序列
- 第五章 - 高频考题(中等)
- 0002. 两数相加
- 0003. 无重复字符的最长子串
- 0005. 最长回文子串
- 0011. 盛最多水的容器
- 0015. 三数之和
- 0017. 电话号码的字母组合
- 0019. 删除链表的倒数第N个节点
- 0022. 括号生成
- 0024. 两两交换链表中的节点
- 0029. 两数相除
- 0031. 下一个排列
- 0033. 搜索旋转排序数组
- 0039. 组合总和
- 0040. 组合总和 II
- 0046. 全排列
- 0047. 全排列 II
- 0048. 旋转图像
- 0049. 字母异位词分组
- 0050. Pow(x, n)
- 0055. 跳跃游戏
- 0056. 合并区间
- 0060. 第k个排列
- 0062. 不同路径
- 0073. 矩阵置零
- 0075. 颜色分类
- 0078. 子集
- 0079. 单词搜索
- 0080. 删除排序数组中的重复项 II
- 0086. 分隔链表
- 0090. 子集 II
- 0091. 解码方法
- 0092. 反转链表 II
- 0094. 二叉树的中序遍历
- 0095. 不同的二叉搜索树 II
- 0096. 不同的二叉搜索树
- 0098. 验证二叉搜索树
- 0102. 二叉树的层序遍历
- 0103. 二叉树的锯齿形层次遍历
- 105. 从前序与中序遍历序列构造二叉树
- 0113. 路径总和 II
- 0129. 求根到叶子节点数字之和
- 0130. 被围绕的区域
- 0131. 分割回文串
- 0139. 单词拆分
- 0144. 二叉树的前序遍历
- 0150. 逆波兰表达式求值
- 0152. 乘积最大子数组
- 0199. 二叉树的右视图
- 0200. 岛屿数量
- 0201. 数字范围按位与
- 0208. 实现 Trie (前缀树)
- 0209. 长度最小的子数组
- 0211. 添加与搜索单词 * 数据结构设计
- 0215. 数组中的第K个最大元素
- 0221. 最大正方形
- 0229. 求众数 II
- 0230. 二叉搜索树中第K小的元素
- 0236. 二叉树的最近公共祖先
- 0238. 除自身以外数组的乘积
- 0240. 搜索二维矩阵 II
- 0279. 完全平方数
- 0309. 最佳买卖股票时机含冷冻期
- 0322. 零钱兑换
- 0328. 奇偶链表
- 0334. 递增的三元子序列
- 0337. 打家劫舍 III
- 0343. 整数拆分
- 0365. 水壶问题
- 0378. 有序矩阵中第K小的元素
- 0380. 常数时间插入、删除和获取随机元素
- 0416. 分割等和子集
- 0445. 两数相加 II
- 0454. 四数相加 II
- 0494. 目标和
- 0516. 最长回文子序列
- 0518. 零钱兑换 II
- 0547. 朋友圈
- 0560. 和为K的子数组
- 0609. 在系统中查找重复文件
- 0611. 有效三角形的个数
- 0718. 最长重复子数组
- 0754. 到达终点数字
- 0785. 判断二分图
- 0820. 单词的压缩编码
- 0875. 爱吃香蕉的珂珂
- 0877. 石子游戏
- 0886. 可能的二分法
- 0900. RLE 迭代器
- 0912. 排序数组
- 0935. 骑士拨号器
- 1011. 在 D 天内送达包裹的能力
- 1014. 最佳观光组合
- 1015. 可被 K 整除的最小整数
- 1019. 链表中的下一个更大节点
- 1020. 飞地的数量
- 1023. 驼峰式匹配
- 1031. 两个非重叠子数组的最大和
- 1104. 二叉树寻路
- 1131.绝对值表达式的最大值
- 1186. 删除一次得到子数组最大和
- 1218. 最长定差子序列
- 1227. 飞机座位分配概率
- 1261. 在受污染的二叉树中查找元素
- 1262. 可被三整除的最大和
- 1297. 子串的最大出现次数
- 1310. 子数组异或查询
- 1334. 阈值距离内邻居最少的城市
- 1371.每个元音包含偶数次的最长子字符串
- 第六章 - 高频考题(困难)
- 0004. 寻找两个正序数组的中位数
- 0023. 合并K个升序链表
- 0025. K 个一组翻转链表
- 0030. 串联所有单词的子串
- 0032. 最长有效括号
- 0042. 接雨水
- 0052. N皇后 II
- 0084. 柱状图中最大的矩形
- 0085. 最大矩形
- 0124. 二叉树中的最大路径和
- 0128. 最长连续序列
- 0145. 二叉树的后序遍历
- 0212. 单词搜索 II
- 0239. 滑动窗口最大值
- 0295. 数据流的中位数
- 0301. 删除无效的括号
- 0312. 戳气球
- 0335. 路径交叉
- 0460. LFU缓存
- 0472. 连接词
- 0488. 祖玛游戏
- 0493. 翻转对
- 0887. 鸡蛋掉落
- 0895. 最大频率栈
- 1032. 字符流
- 1168. 水资源分配优化
- 1449. 数位成本和为目标值的最大数字
- 后序